AI智能体以后不能想干嘛就干嘛了。前脚AI Agent赛道火得一塌糊涂,后脚监管就来了——国家网信办、国家发展改革委、工业和信息化部三部门联合印发了《智能体规范应用与创新发展实施意见》,给AI智能体的发展套上了”笼子”。
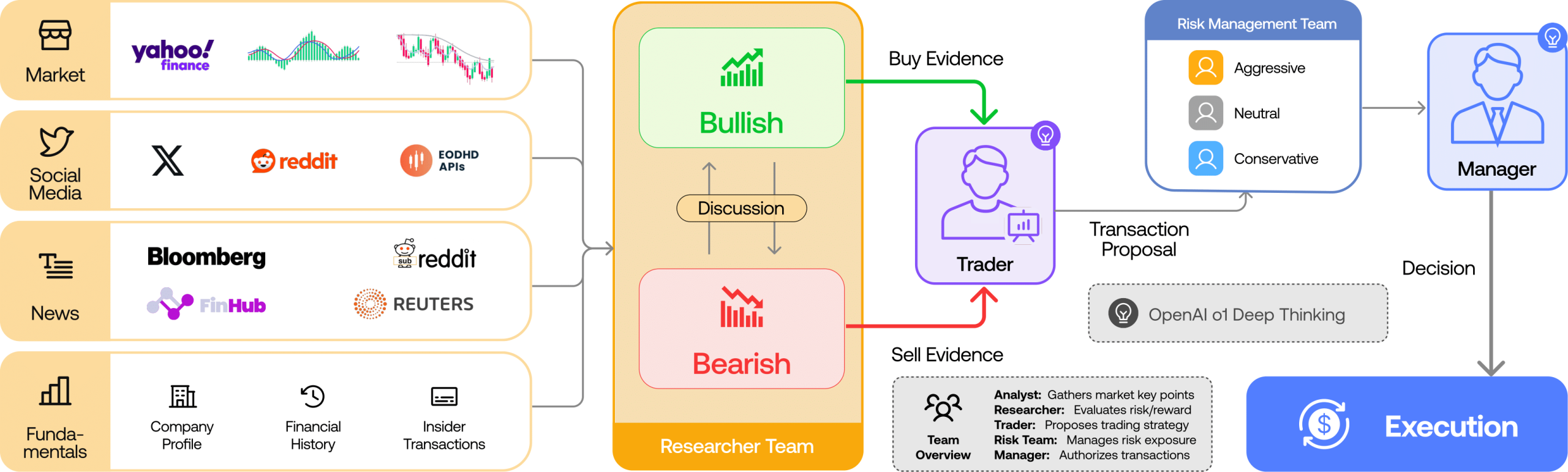
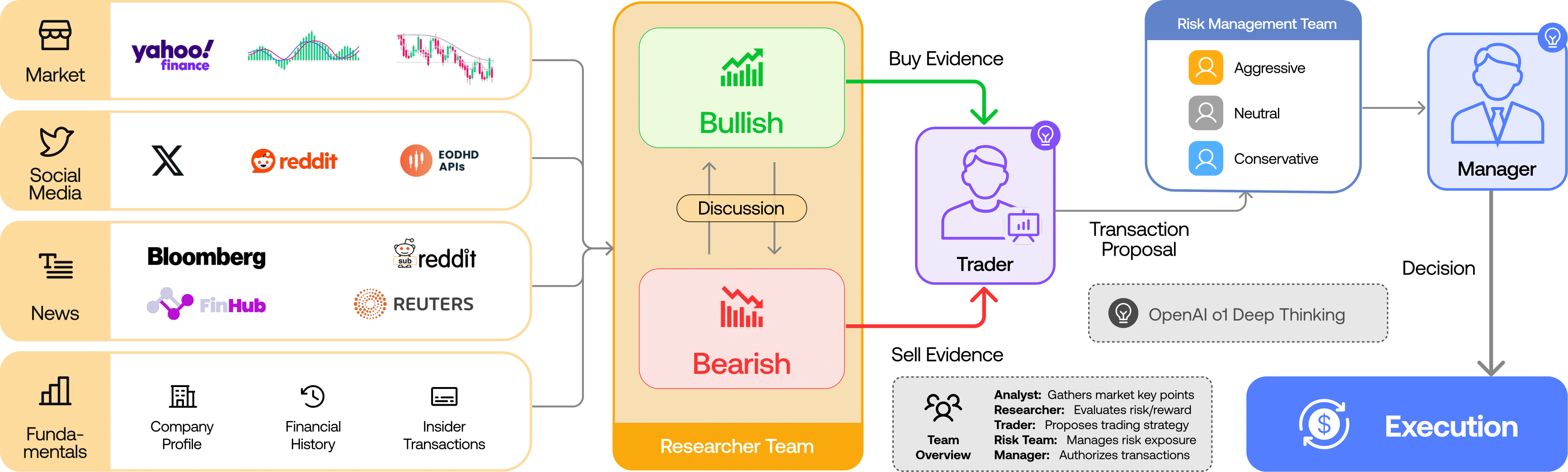
智能体是什么?说白了就是能自己干活儿的AI
官方给智能体下了个定义:具备自主感知、记忆、决策、交互与执行能力的智能系统。翻译成人话就是——它能自己看、自己想、自己做决定、自己干活。随着大模型技术成熟,智能体正在加速跟网络空间、物理世界深度融合,这玩意儿要是不管一管,确实容易出事儿。
智能体决策权限划分为三个层级:仅限用户本人决策、需由用户授权决策、智能体自主决策——明确划定各种决策方式的合理边界及所需权限
安全可控是底线,创新驱动是方向
《意见》提出了四大基本原则:安全可控、规范有序、创新驱动、应用牵引。具体举措主要围绕四个方面:夯实技术底座和标准协议、守牢安全底线和防范风险、强化19个典型应用场景牵引、建设创新生态促进产业合作。
19个场景定了哪些方向?
应用场景覆盖五大方向:科学研究、产业发展、提振消费、民生福祉、社会治理。《意见》还提出了一个量化目标:新一代智能终端、智能体等应用普及率要超70%。说实话,这个覆盖率目标挺激进的,意味着三年内智能体要从”尝鲜”变成”标配”。
我觉得这次监管来得挺及时的。之前看到各种AI Agent产品一个比一个激进,各种”全自动”、”自主执行”吹得天花乱坠,普通用户根本搞不清楚这些AI到底能自己做什么主。现在好了,官方给你划清楚——哪些必须人拍板、哪些可以授权、哪些AI能自己定。这有点像给AI立了个”交规”,接下来就看执行力度了。
📎 原文来源:三部门发文规范AI智能体发展 规范与创新并举(财新网)