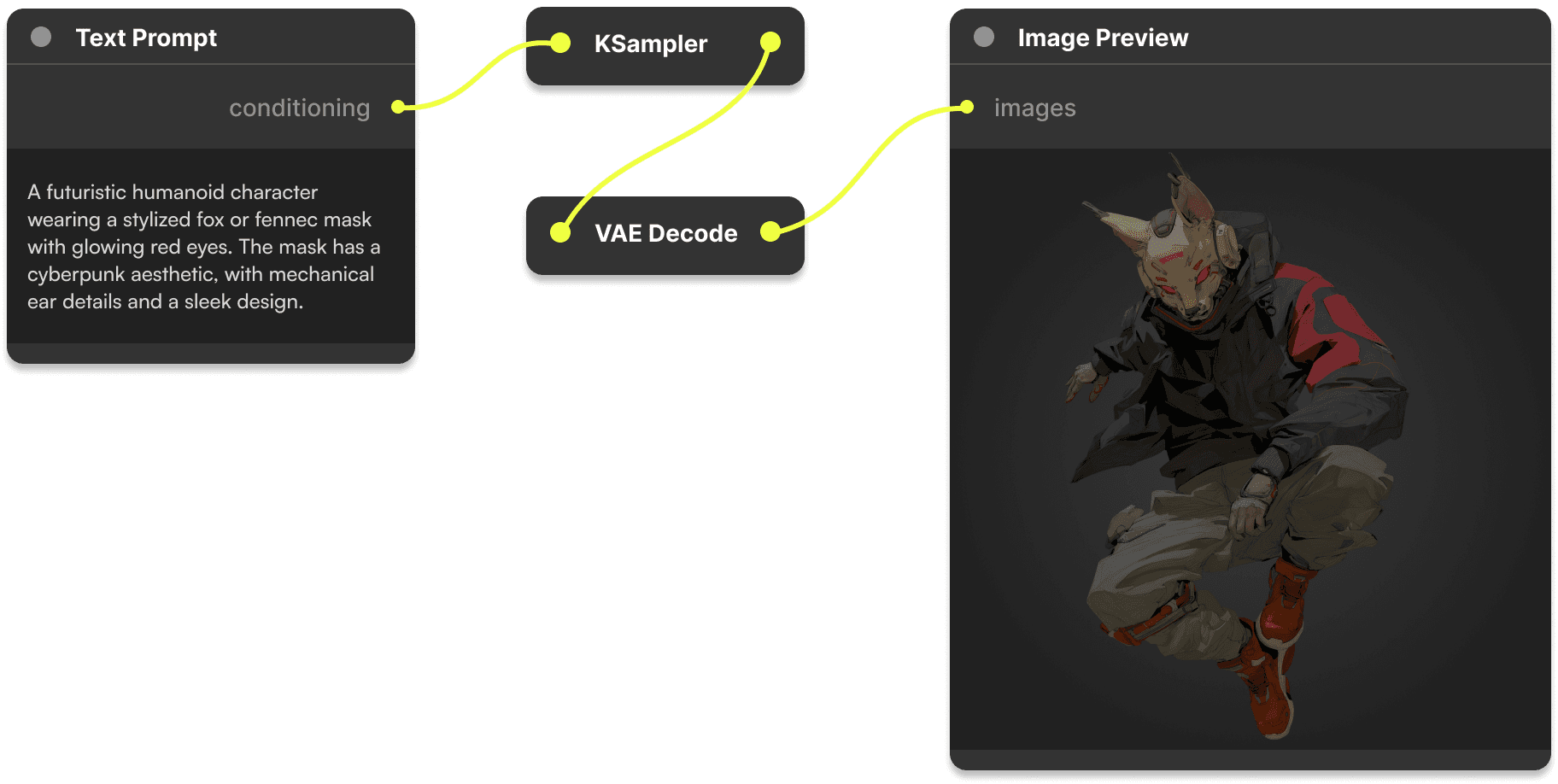
5月19日,智象未来在北京办了首届开放日,主题叫「Imagining the World」。会上最重磅的消息,是发布了参数超两千亿的图像大模型HiDream-O1-Image-Pro。
告别「拼接味」,原生全模态才是正路
现在市面上的图像生成模型,大多还是「拼接路线」——图像走一条路,文本走另一条路,最后拼在一起。这种做法在复杂语义理解、精准文字渲染上总是差点意思。
HiDream-O1-Image-Pro换了个思路:把图像像素、文本标记和任务条件统一放进一个连续共享的标记空间,从底层就开始「混着学」。这个架构叫Unified Transformer(UiT),智象未来管它叫「原生全模态」。
「当前很多『多模态大模型』,本质上还是『单模态拼接』。而原生多模态,是从一开始就把『世界的规则』刻进模型里——它知道物理定律、空间关系、因果逻辑,所以它能真正理解世界、推理世界,而不只是『生成内容』。」

开源版已经打遍榜上无敌手
其实在这之前,智象未来已经把8B参数的开源版本HiDream-O1-Image放到了全球评测平台Artificial Analysis上,结果在文生图开源模型里排到了全球第一,超过了Z-Image Turbo、Qwen-Image、FLUX.2这些主流对手。
这次发布的Pro版是闭源版本,参数直接干到了两千亿以上,在复杂文本渲染、指令编辑、多主体个性化这些任务上全面刷新了SOTA纪录。
半月内连融两轮,资本用脚投票
开放日上还透露了一个信号:公司融资在提速。不久之前刚完成超5亿元融资,半月之内又敲定了新一轮,投资方包括深创投、金浦投资、财鑫资本、复聚资本等。
现在的阵容很有意思:安徽、上海、湖南、杭州的多方产业基金在跟,深创投、东方富海、峰华资本这些头部市场化VC也在押注。这个资本组合,摆明了是要在「原生全模态」这个方向上重仓。
商业化落地:三个智能体产品已经跑起来
光有模型不够,智象未来同时亮出了三条产品线:
- HiBurst:商业营销智能体,已覆盖TikTok、Meta、抖音、小红书等平台,是TikTok官方top5服务商,年生产电商营销视频超百万条
- 帧赞:全球首个专业级AI影视创作智能体,已累计制作短漫剧超5000分钟
- vivago:社媒创作智能体,近日登上Product Hunt日榜第一,覆盖全球100多个国家超4000万用户
从视觉生成走向世界模型,这条路还长。但智象未来至少证明了一件事:原生全模态架构不是空中楼阁,它已经能打商业仗了。