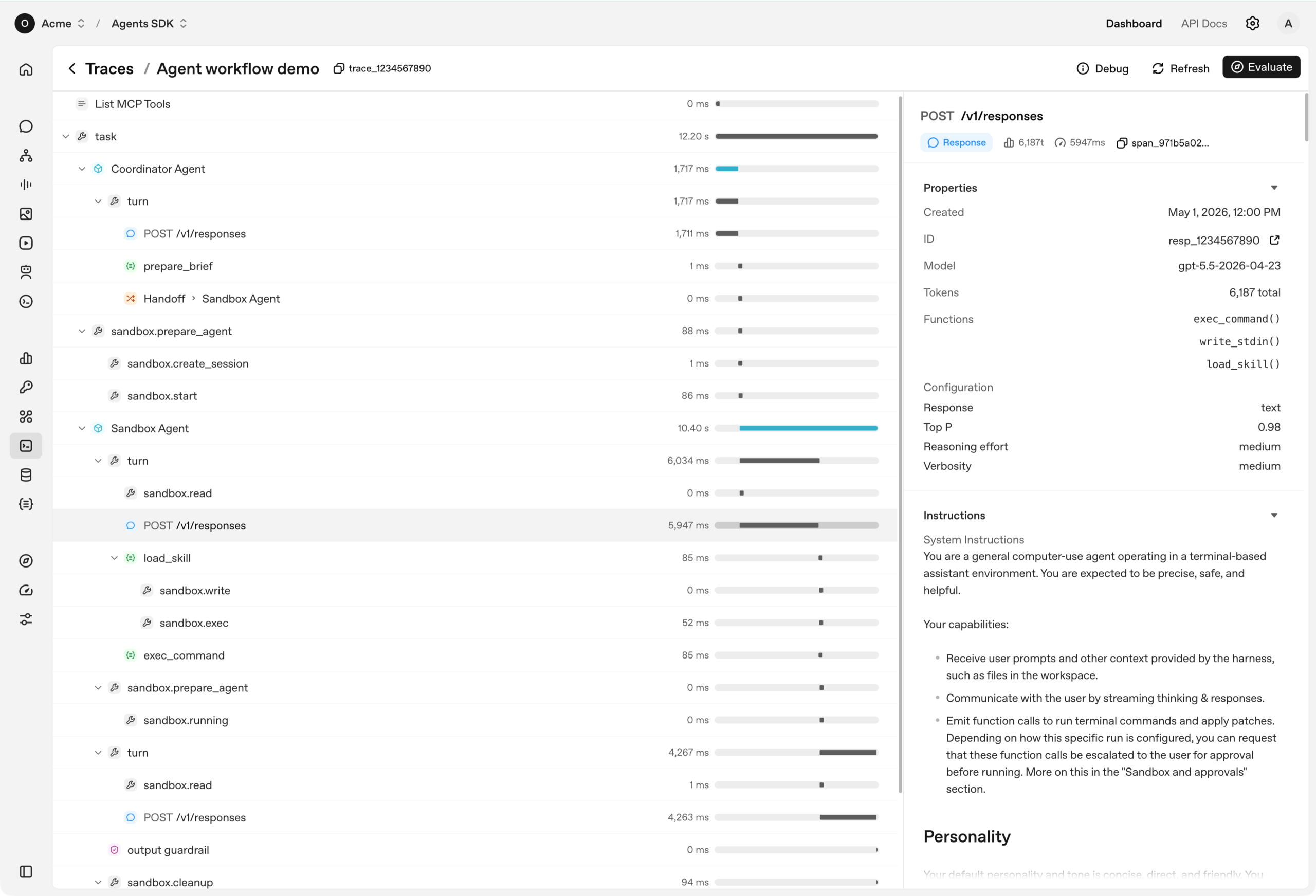
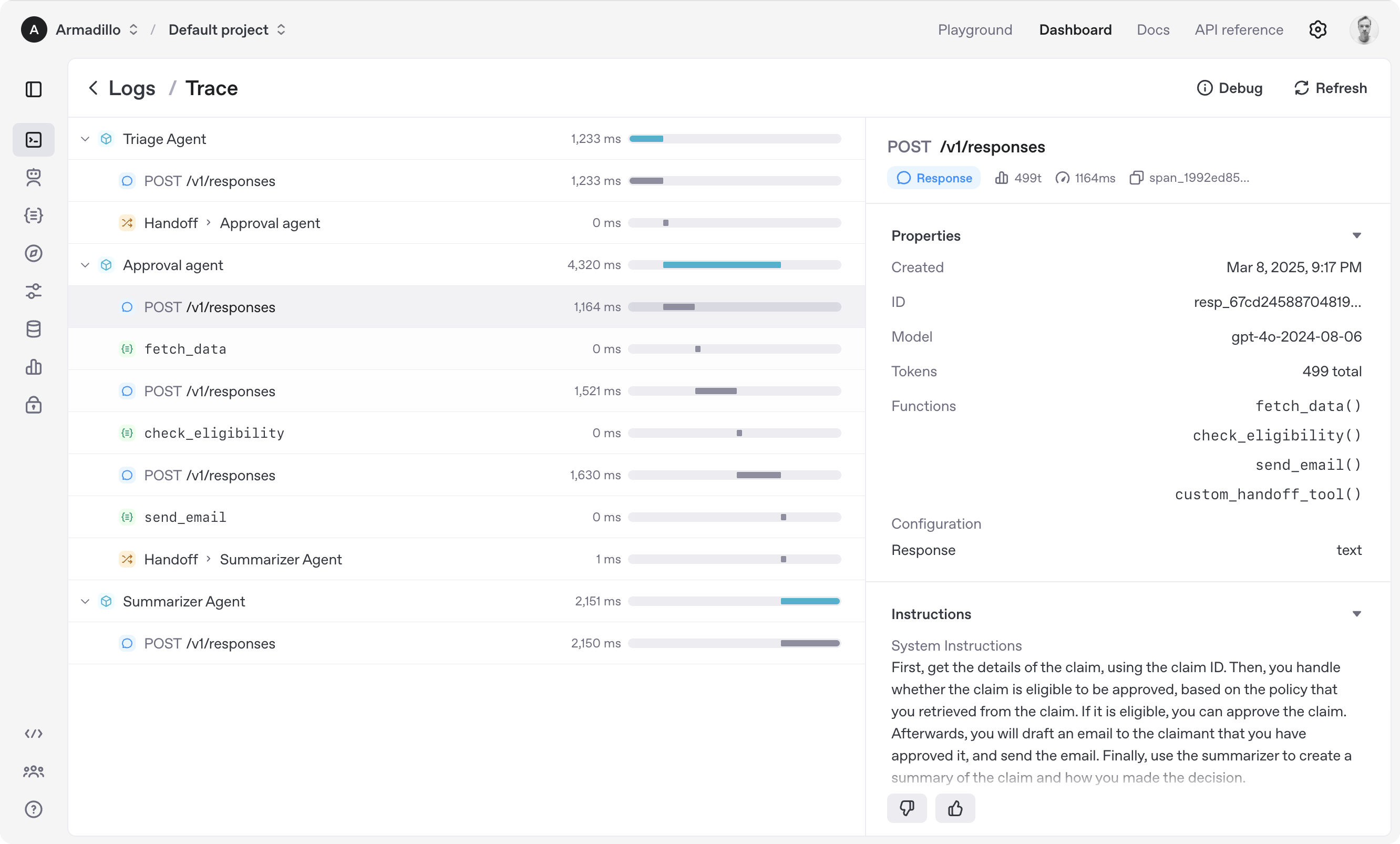
OpenAI Agents SDK 多智能体编排架构示意图(图片来源:OpenAI 官方文档)
项目简介
OpenAI Agents SDK 是 OpenAI 官方出品的轻量级、强大的多智能体工作流编排框架,2025年3月开源,至今已获得 27,470+ Stars 和 4,227 Forks。一句话概括:让你用极简的 Python 代码,构建生产级的多智能体 AI 应用。
与 LangChain、AutoGen 等第三方框架不同,Agents SDK 是 OpenAI 官方原生维护,与 OpenAI API 深度集成,同时支持 100+ 其他 LLM(通过 LiteLLM),真正做到了 provider-agnostic(提供商无关)。
🌟 核心定位:不是另一个 AI 框架,而是 OpenAI 对「如何构建 Agentic AI 应用」的官方最佳实践。如果你在用 GPT/Claude 构建智能体应用,这是目前最权威的参考实现。
安装要求和过程
环境要求
- Python:3.10 及以上版本
- 依赖:Pydantic v2、httpx、mcp-python-sdk
- API Key:OpenAI API Key(或兼容的其它 LLM)
快速安装
# 使用 pip(推荐) pip install openai-agents # 使用 uv(更快) uv add openai-agents # 语音功能支持(可选) pip install 'openai-agents[voice]' # Redis 会话支持(可选) pip install 'openai-agents[redis]'
最小可运行示例
import os
from agents import Agent, Runner
# 设置 API Key(支持任何兼容 OpenAI API 的服务)
os.environ["OPENAI_API_KEY"] = "your-api-key"
agent = Agent(
name="Assistant",
instructions="你是一个有帮助的助手。",
)
result = Runner.run_sync(agent, "用一句话解释什么是 MCP?")
print(result.final_output)
核心功能
🤖 1. Agents — 智能体定义
通过声明式 API 定义智能体:配置指令(instructions)、工具(tools)、安全护栏(guardrails)和交接策略(handoffs)。每个 Agent 是一个独立的 LLM 调用上下文。
🔄 2. Handoffs — 智能体交接
一个智能体可以将对话「交接」给另一个智能体,实现专业分工。例如: triage Agent → 路由到 billing Agent / technical Agent,是构建多智能体系统的核心机制。
🛡️ 3. Guardrails — 输入/输出安全护栏
可配置的安全检查,在 Agent 执行前后验证输入和输出。支持自定义 guardrail 函数,实现内容审核、敏感信息过滤、输出格式校验等。
🔧 4. Tools + MCP — 工具与协议扩展
支持函数工具(function tools)、MCP 服务器工具、托管工具(web search / file search / computer use)。MCP 协议原生支持,可接入 1000+ 工具生态。
📊 5. Tracing — 内置可观测性
所有 Agent 运行自动记录追踪信息,可在 OpenAI Traces Dashboard 查看、调试和优化工作流。无需额外配置,开箱即用。
📦 6. Sandbox Agents — 容器化工作空间
v0.14.0 新增功能。Agent 可以在隔离的容器环境中执行真实工作(读写文件、运行命令、应用补丁),支持长时间跨会话的任务。可用于代码审查、自动修复等场景。
🎙️ 7. Realtime Agents — 语音智能体
基于 gpt-realtime-2 模型构建语音智能体,支持实时语音对话,完整集成 Agent 所有功能(工具调用、handoffs、guardrails)。可用于构建 AI 客服、语音助手等。
💬 8. Sessions — 会话历史管理
自动管理跨多次运行的对话历史,开发者无需手动维护上下文。支持 Redis 持久化,适合生产环境。
典型使用场景
场景一:客户服务多智能体系统
构建一个客服系统,用户消息首先进入 Triage Agent,根据问题类型自动交接给:
- Billing Agent:处理账单、退款、付费问题
- Technical Agent:处理技术故障、错误排查
- Escalation Agent:复杂问题升级人工处理(Human-in-the-loop)
每个专业 Agent 有自己的指令、工具和知识库,Handoffs 实现无缝切换。Guardrails 确保用户输入和 Agent 输出符合安全规范。
场景二:AI 编程助手(代码审查+自动修复)
利用 Sandbox Agents 在隔离环境中运行 AI 编程助手:
- Agent 克隆代码仓库到沙箱
- 阅读代码、分析 Issue
- 生成修复方案并执行测试
- 自动提交 PR
整个过程在沙箱中完成,不影响生产环境。支持跨长时间任务(分钟级到小时级)。
场景三:语音 AI 助手(Realtime Agent)
基于 Realtime Agents 构建语音助手:
- 用户通过语音提问
gpt-realtime-2实时理解并响应- Agent 调用工具(查天气、搜信息、控制智能家居)
- 支持中断、插话、多轮对话
可用于 AI 客服热线、语音笔记助手、语言学习陪练等场景。
推荐理由
作为一个深度使用过 LangChain、AutoGen、CrewAI 等框架的开发者,OpenAI Agents SDK 是目前我最推荐的入门和生产级多智能体框架,原因如下:
- 官方背书,长期维护有保障:由 OpenAI 官方团队维护,与 OpenAI API 深度集成,未来能力(如 Realtime API、Computer Use)会第一时间支持。不用担心框架突然停更。
- 设计极简,学习曲线平缓:核心概念只有 Agents / Handoffs / Tools / Guardrails / Tracing 五个,API 设计直观。相比 LangChain 的复杂抽象,Agents SDK 让你专注于业务逻辑。
- Provider-agnostic,不绑定 OpenAI:虽然由 OpenAI 维护,但通过 LiteLLM 支持 100+ LLM(Anthropic / Gemini / DeepSeek / 本地 Ollama 等)。你可以在开发时用 GPT-4o,生产时切换到更便宜的模型。
- 内置 Tracing,调试不再抓瞎:所有 Agent 运行自动记录到 OpenAI Platform,可以查看每次 LLM 调用、工具执行、handoff 传递的完整链路。这是其他框架需要自己搭建的可观测性系统。
- 生产级特性齐全:Guardrails(安全护栏)、Human-in-the-loop(人工介入)、Sessions(会话管理)、沙箱隔离,这些都是生产环境必需但很多框架忽视的特性。
⚠️ 注意事项:Agents SDK 是 Python-first 框架,如果你需要 JS/TS 版本,可以查看 openai-agents-js。另外,Tracing 功能默认将数据传输到 OpenAI Platform,如数据隐私有要求,可以配置自定义 tracing processor。
项目数据一览
| 指标 | 数据 |
|---|---|
| GitHub Stars | 27,470+ ⭐ |
| Forks | 4,227 |
| 主要功能 | 多智能体编排、Handoffs、Guardrails、Tracing、MCP、Sandbox Agents、Realtime |
| 编程语言 | Python(也支持 JS/TS) |
| 开源许可 | MIT License |
| 维护方 | OpenAI 官方 |
| 创建时间 | 2025年3月11日 |
| 最后更新 | 2026年6月27日(非常活跃 🔥) |
下载地址
🚀 OpenAI Agents SDK 让构建生产级多智能体应用变得简单而强大。如果你正在做 AI Agent 项目,这应该是你的首选框架。