🎨 项目简介
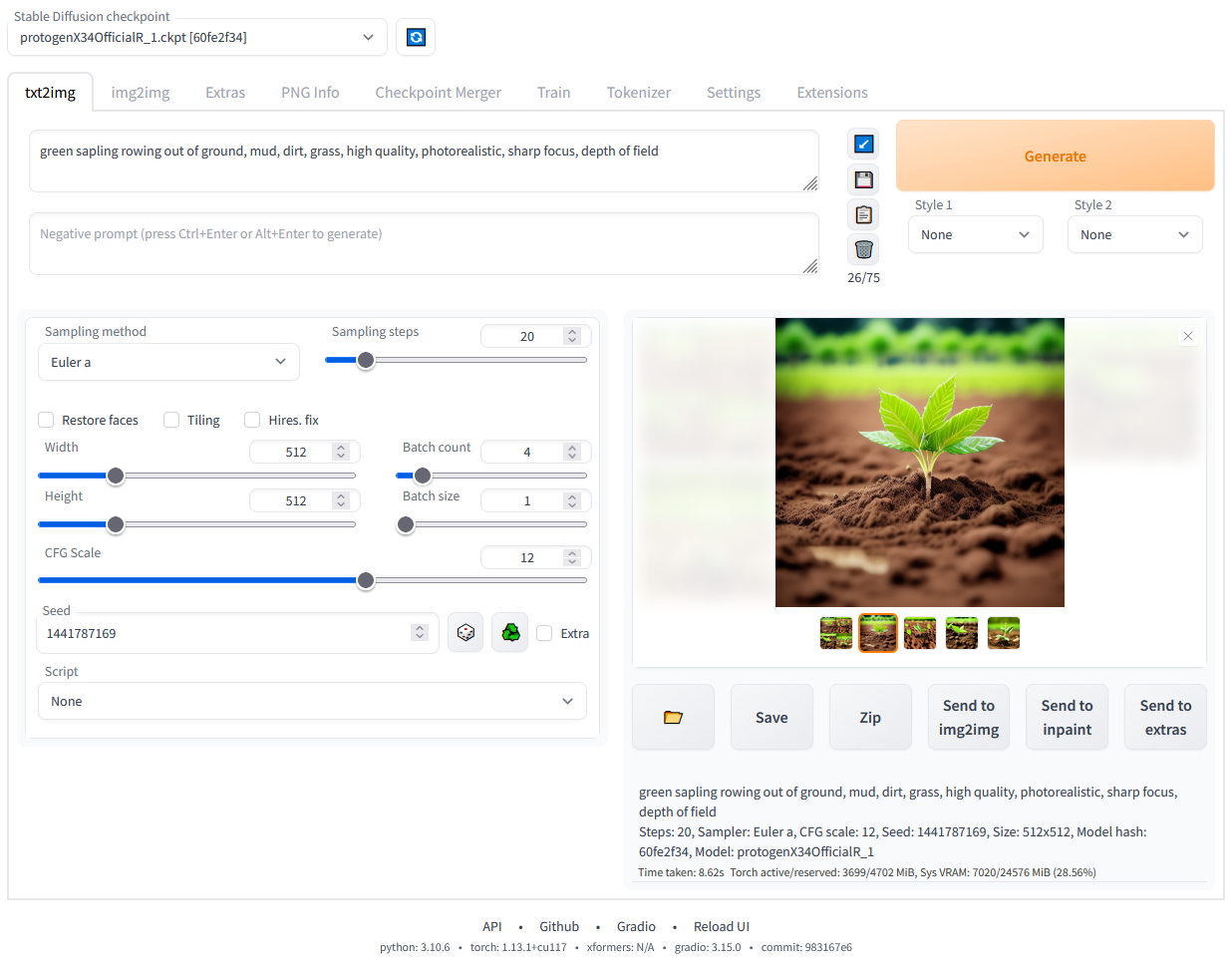
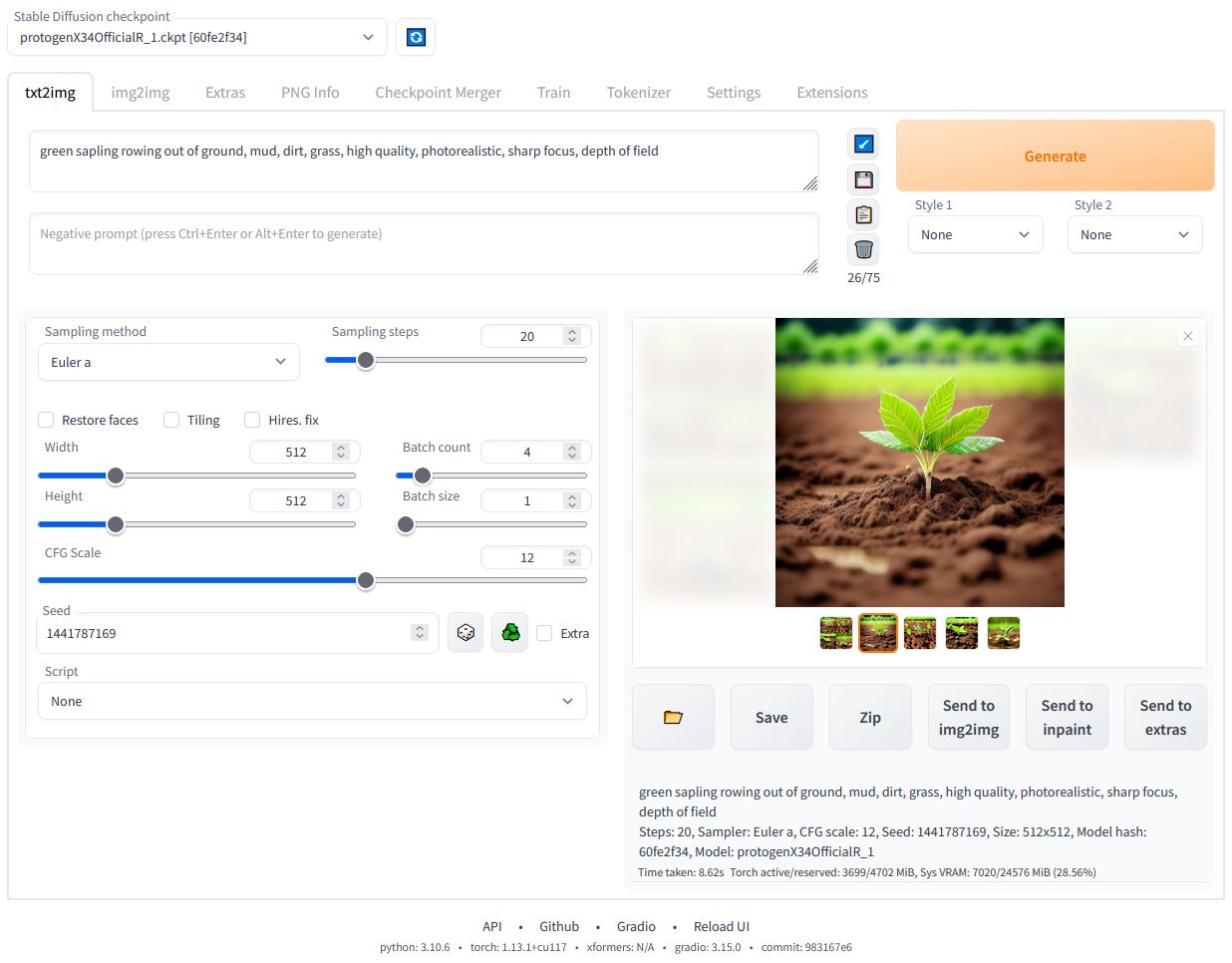
Stable Diffusion WebUI 是由 AUTOMATIC1111 开发的基于 Gradio 框架的 Stable Diffusion 浏览器交互界面,是 AI 图像生成领域最流行、功能最完整的开源工具。只需简单部署,即可在浏览器中完成文生图、图生图、模型训练、参数微调等全流程 AI 绘画操作。
📦 最流行 AI 绘画工具
🔧 丰富扩展生态
💻 本地私有部署
⚙️ 安装要求和过程
环境要求
- Python 3.10.6(更高版本可能不兼容 torch)
- Git
- NVIDIA 显卡(推荐 4GB+ 显存,2GB 也可运行)
- 或 AMD 显卡 / Intel 核显 / Apple Silicon(需参考对应安装指南)
Windows 快速安装(推荐方式)
下载 v1.0.0-pre 版本的 sd.webui.zip
解压后依次运行 update.bat 和 run.bat 即可
# 方式2:源码安装
1. 安装 Python 3.10.6(勾选 “Add Python to PATH”)
2. 安装 Git
3. 克隆仓库:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. 双击运行 webui-user.bat
Linux 安装
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
./webui.sh
🚀 核心功能
💡 典型使用场景
输入自然语言提示词(如 “a fantasy castle on a floating island, digital art, trending on ArtStation”),即可生成高质量 AI 艺术作品。通过 Negative Prompt 排除不想要的元素,使用 X/Y/Z plot 批量测试不同参数组合,快速找到最佳生成配置。
上传参考图片,配合提示词进行风格转换(如将照片转为动漫风格、油画风格)。支持 Denoising strength 控制与原图的相似度,配合 Inpainting 可精确重绘指定区域(如更换人物服装、修改背景)。
使用 Training 标签页训练自己的 Textual Inversion 嵌入或 LoRA 模型,只需几十张样本图片即可学习特定人物、风格或物品特征。训练完成后一键加载,在生成中调用自定义概念,实现个性化 AI 绘画。
🌟 推荐理由
Stable Diffusion WebUI 是 AI 绘画领域毫无争议的标杆工具。作为 GitHub 上 Star 数最多的 Stable Diffusion 界面(163K+),它不仅功能全面,更重要的是拥有最活跃的社区和扩展生态——目前已有数千个自定义脚本和扩展插件,覆盖从人脸修复、批量处理到 ComfyUI 工作流集成的各类需求。
与云端 AI 绘画服务(如 Midjourney)相比,WebUI 的最大优势是完全本地运行,无需付费订阅,数据隐私有保障,且支持任意开源 Stable Diffusion 模型(SD1.5/SD2.0/SDXL/SD3 等)。对显存的要求也相当亲民——4GB 显存即可流畅运行,甚至 2GB 也有成功案例。
无论你是 AI 艺术创作者、游戏美术设计师,还是仅仅对 AI 绘画感兴趣的爱好者,Stable Diffusion WebUI 都是最好的起点。一键安装脚本让部署变得异常简单,丰富的教程资源和社区支持也能帮助你快速上手。
📥 下载地址
Stable Diffusion
图像生成
本地部署
开源