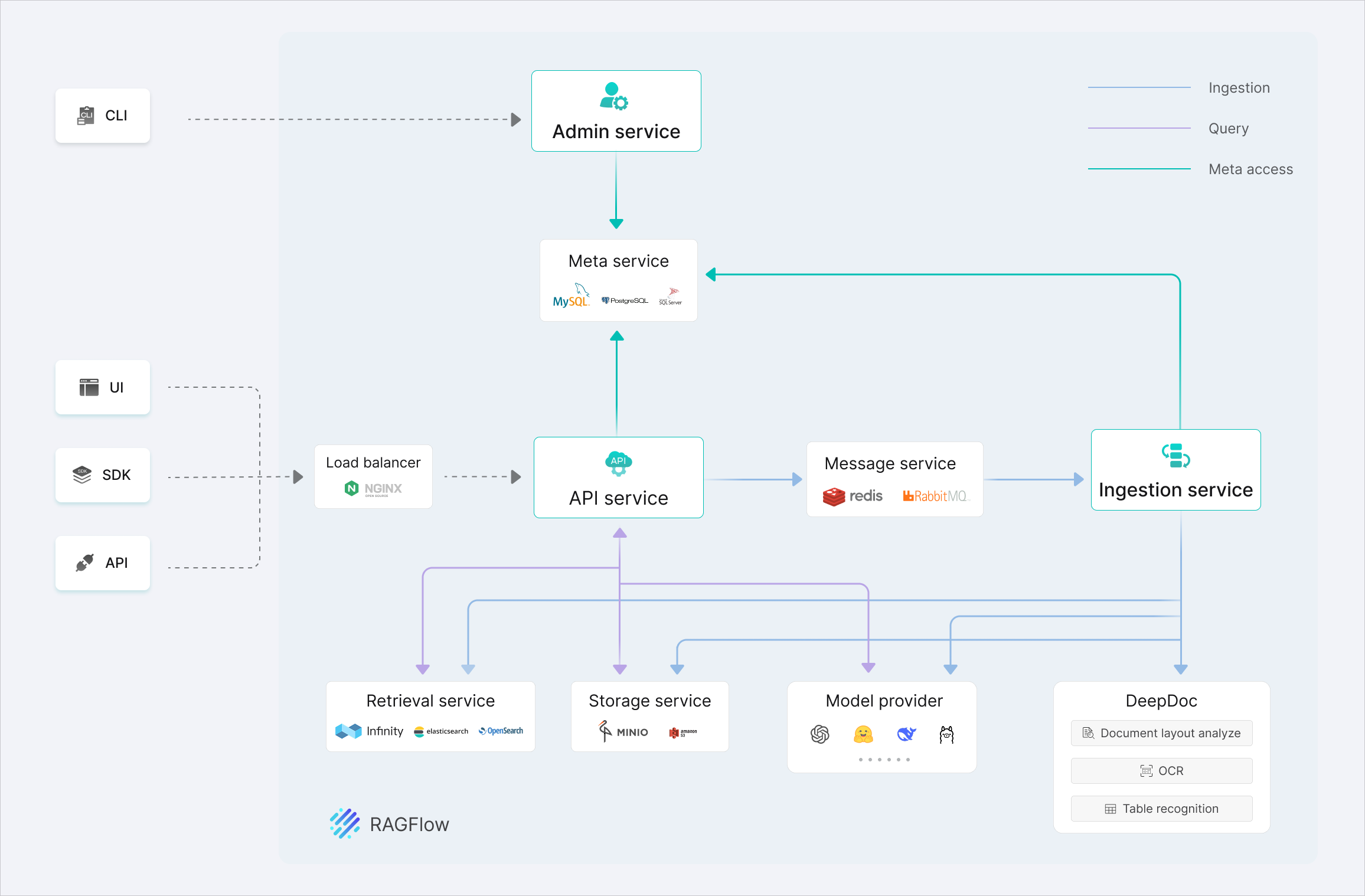
📌 项目简介
LobeChat 是 LobeHub 团队开发的开源 AI 聊天框架,也是 GitHub 上 Star 数最多的开源 AI 客户端之一(72K+ Stars)。它支持 Web 和桌面两种形式,在一个界面里同时接入 GPT、Claude、Gemini、DeepSeek、Ollama 等 80+ 模型,还内置插件市场、RAG 知识库、多模型对比等实用功能。最重要的是——完全免费开源,数据可完全本地化。
1
安装要求和过程
环境要求
| 部署方式 | 环境要求 |
|---|---|
| Web 版 | 浏览器访问,无需安装 |
| 桌面版 | Windows/macOS/Linux,下载安装包 |
| Docker | Docker + Docker Compose |
| 本地开发 | Node.js 18+, pnpm, Git |
快速安装(桌面版)
# 1. 从 GitHub Releases 下载对应平台安装包
https://github.com/lobehub/lobe-chat/releases
# Windows: LobeChat-win.exe
# macOS: LobeChat-mac.dmg
# Linux: LobeChat-linux.AppImage
Docker 部署(自托管推荐)
# 拉取镜像并启动
docker run -d -p 3210:3210 \
-e OPENAI_API_KEY=your-key \
–name lobechat lobehub/lobe-chat
2
核心功能
🤖 多模型统一接入
支持 OpenAI、Claude、Gemini、DeepSeek、Kimi、智谱、Ollama 等 80+ 模型,一个界面随意切换。自定义 Base URL,可接入任何兼容 OpenAI 协议的 API。
🔌 插件市场 + MCP 集成
内置 40+ 插件,联网搜索、代码执行、图片生成开箱即用。支持 MCP 协议,可一键接入 AI Agent 工具链,扩展能力无上限。
📚 RAG 知识库
上传 PDF、Word、网页,自动建立向量索引。基于个人知识库问答,适合企业文档、技术手册、合同条款等场景。本地向量数据库,数据不出门。
⚡ 多模型对比 + 语音对话
同一问题多模型同时回答,横向对比 Claude/GPT/Gemini 差异。内置 TTS/STT,支持语音对话。还有「助手市场」,几百个预设专业助手直接可用。
🏠 完全自托管 + 隐私优先
Docker 一键部署,数据全留本地。MIT 开源,可自由修改分发。对比 ChatGPT Plus $20/月,LobeChat 客户端免费,只需按 API 用量付费。
3
典型使用场景
🎯 场景一:多模型对比选型
在模型选型阶段,同一个 Prompt 同时发给 Claude Opus、GPT-5.4、Gemini 2.5 Pro,直接对比输出质量,不再靠猜。LobeChat 的多模型对比功能让选型决策有数据支撑。
📚 场景二:企业知识库问答
将公司技术文档、产品手册、合同模板上传到 LobeChat 知识库,基于 RAG 检索增强生成,精准回答内部问题。支持 Docker 私有化部署,数据完全不出企业内网。
💻 场景三:开发者日常助手
配置 DeepSeek V3(中文代码能力强,价格低)+ Claude Sonnet(复杂逻辑)+ GPT-5.4(多模态),不同任务自动切换最合适模型。助手市场里的「代码审查」「SQL 优化」等预设助手,开箱即用。
💡 推荐理由
我用过不少 AI 客户端,LobeChat 是最顺手的选择之一,原因如下:
- ✅ 真的免费:客户端 MIT 开源,桌面版零成本,只需付 API 费用(比 ChatGPT Plus 灵活太多)
- ✅ 真的开放:不绑定任何厂商,自定义 Base URL 接入任何兼容 API,甚至支持本地 Ollama
- ✅ 真的好用:界面现代美观,多模型对比、知识库、插件市场一应俱全,功能深度足够
- ✅ 真的私密:Docker 一键自托管,数据 100% 本地,适合对隐私有要求的企业和个人
如果你同时用多个 AI 模型,或者不想把数据交给 OpenAI,LobeChat 是目前最好的开源替代方案。
📥 下载地址
许可协议:MIT License | 语言:TypeScript | 支持平台:Web / Windows / macOS / Linux / Docker
⚠️ 本文基于公开资料整理,项目数据截至 2026 年 6 月。LobeChat 与 LobeHub 为同一团队产品,功能持续迭代中。