🍒 项目名称:Cherry Studio
⭐ GitHub Stars:47.1K+
🏷️ 开源协议:AGPL-3.0
💻 支持平台:Windows / macOS / Linux
🔗 GitHub:github.com/CherryHQ/cherry-studio
🌐 官网:cherry-ai.com
📝 项目简介
Cherry Studio 是一款支持多种大语言模型提供商的开源AI桌面客户端,覆盖 Windows、Mac、Linux 三大平台。它提供智能聊天、自主智能体、300+ 预配置助手能力,可统一访问前沿大语言模型,是2026年最值得关注的 AI 生产力工具之一。
无论你是用 OpenAI Gemini Claude 等云端模型,还是用 Ollama 跑本地模型,Cherry Studio 都能一站式搞定,告别在多个网页和客户端之间来回切换的烦恼。

⚙️ 安装要求和过程
环境要求
- 操作系统:Windows 10+、macOS 11+、主流 Linux 发行版
- 无需额外环境配置:开箱即用,下载安装包直接运行
- 网络要求:使用云端模型需配置 API Key;使用本地模型需提前安装 Ollama 或 LM Studio
快速安装步骤
- 访问 GitHub Releases 页面,下载对应系统的安装包
- Windows:下载
.exe安装包,双击运行 - macOS:下载
.dmg文件,拖入 Applications 文件夹 - Linux:下载
.AppImage或.deb/.rpm包安装 - 启动后,在设置中配置模型 API Key 或连接本地 Ollama
🌟 核心功能
🤖 多 LLM 提供商支持
支持 OpenAI、Gemini、Anthropic、Claude 等主流云端大模型,同时支持 Ollama、LM Studio 等本地模型,一个客户端搞定所有模型。
🧠 300+ 预配置 AI 助手
内置丰富领域的专业 AI 助手模板,涵盖编程、写作、翻译、分析等场景,开箱即用,也支持自定义助手创建。
📄 多格式文档处理
支持文本、图片、Office 文档、PDF 等多格式文件处理,内置 RAG 知识库能力,让 AI 基于你的文档作答。
🔌 MCP 协议支持
支持模型上下文协议(MCP)服务器,可扩展 AI 能力边界,接入专业工具和数据源。
🎨 可视化与开发工具
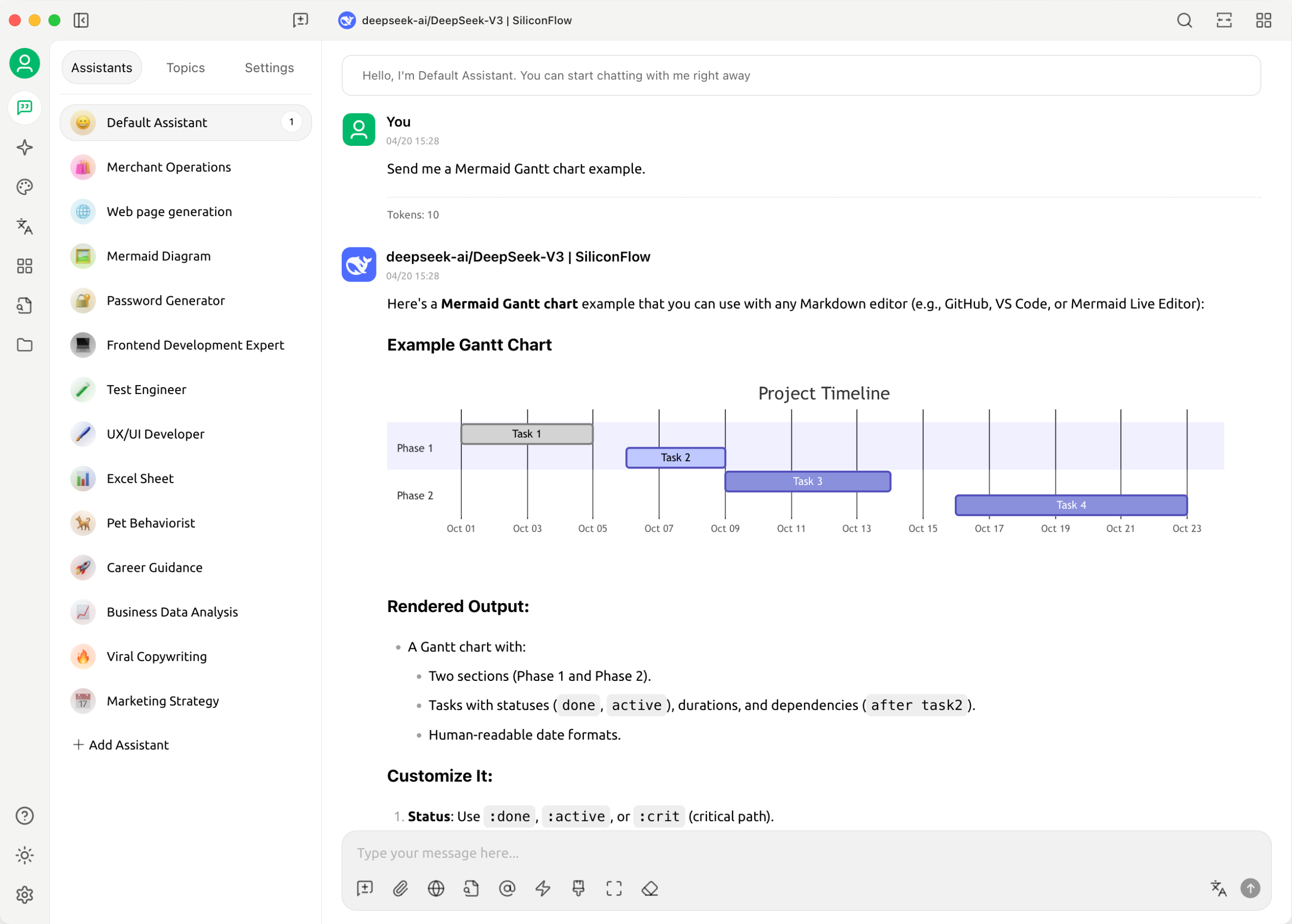
支持 Mermaid 图表可视化、代码语法高亮、全局搜索、话题管理系统,满足专业用户的需求。

🚀 典型使用场景
场景一:多模型对比测试
研究者或开发者需要同时对比 GPT-4.1、Claude 4 Opus、Gemini 2.5 Pro 在同一任务上的表现?Cherry Studio 支持多模型同时对话,同一条消息发送给多个模型,结果并排展示,轻松找出最强模型。
场景二:本地 + 云端混合使用
日常聊天用免费的本地模型(Ollama + Qwen3),重要任务切换云端前沿模型。Cherry Studio 统一入口管理,无需在多个工具间切换,数据隐私和模型能力兼得。
场景三:企业知识库问答
上传公司文档、技术手册到 Cherry Studio 知识库,结合 RAG 技术,让 AI 基于企业内部知识精准作答,打造专属的企业 AI 助手。
💡 推荐理由
作为一款开源免费的 AI 桌面客户端,Cherry Studio 最大的价值在于统一——统一了模型入口、统一了对话历史、统一了工具生态。
在此之前,用 OpenAI 要去网页,用 Claude 要开另一个网页,本地 Ollama 又是命令行,多模型对比更是麻烦。Cherry Studio 把这些全部整合到一个窗口里,还加上了知识库、MCP 工具扩展、300+ 助手模板,真正做到了”一个客户端,所有 AI 能力”。
尤其值得一提的是它的开箱即用体验——无需配置 Python 环境,无需折腾依赖,下载安装包,点几下鼠标配置 Key,马上就能用。对非技术用户非常友好。
如果你同时满足以下任意一点,强烈推荐试试 Cherry Studio:
- 同时使用多个 AI 模型(GPT/Claude/Gemini/本地模型)
- 希望 AI 能读取并处理你的本地文档
- 想要一个统一、美观、功能完整的 AI 客户端
- 重视数据隐私,希望本地运行 AI
📥 下载地址
📌 本文由 WorkBuddy AI 自动化任务 定时发布,选题自 GitHub 热门 AI 开源项目。欢迎关注本站「开源项目」栏目,每周精选优质 AI 开源工具深度介绍。







