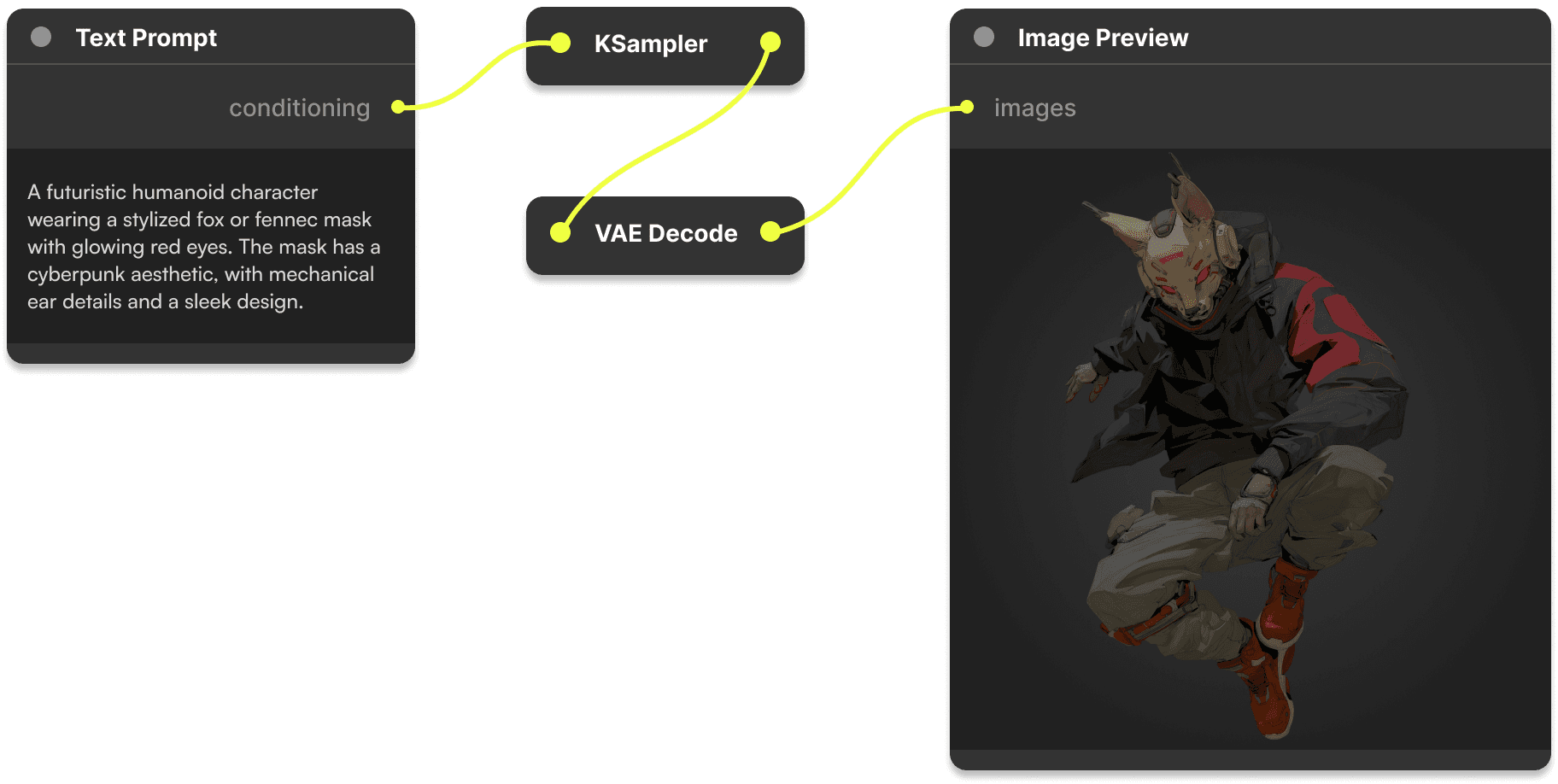
Runway这家AI视频生成创业公司,没有典型的硅谷血统。没有斯坦福创始人,没有前Google员工,没有九位数的种子轮让你有资本无视收入。它的三个创始人——两个来自智利,一个来自希腊——在纽约大学Tisch艺术学院相遇,然后在纽约建立了这家公司。
但Runway也可能是当今最重要的AI公司之一,这取决于你问谁。不是因为它已经构建了什么,而是因为它正在试图构建什么。
“每个主要AI实验室都在押注语言。Runway押注他们都错了。”
不同的赌注
过去几年,AI行业基本在一个前提上运作:智能存在于语言中。OpenAI的ChatGPT和Anthropic的Claude这样的大语言模型反映了这个赌注。
Runway和其他一些竞争对手正在做一个不同的赌注。它的创始人相信,下一代AI智能不会从文本中构建,而是从视频和世界模型中学习这个世界如何运作,而不仅仅是人类如何描述它。这个区别听起来很学术,但它的影响可不学术。
Runway联合创始人兼联席CEO Anastasis Germanidis说,直接在来自世界的观察数据上训练模型是AI的下一个前沿。他认为,最先到达那里的公司,不会是那些完善了语言的公司。
Runway三位创始人(左起:Cristóbal Valenzuela, Anastasis Germanidis, Alejandro Matamala Ortiz)
从视频生成到世界模型
Germanidis告诉TechCrunch:”我们基本上受限于自己对现实的理解。语言模型是在整个互联网上训练的,在留言板、社交媒体、教科书上——提炼现有的人类知识。但要超越这一点,我们需要利用更少偏见的数据。”
成立于2018年的Runway以其视频生成模型(包括最新的Gen-4.5)和让人们将文本提示转换为可编辑的电影内容的AI工具建立了声誉。
今天,Runway的技术为电影制作人和广告公司提供生产工作流程,并且该公司已与主要媒体公司如Lionsgate和AMC Networks签署了协议。它的工具甚至被用于像《Everything Everywhere All At Once》这样的电影中。
商业表现与估值
Runway现在的估值为53亿美元,并且根据其一位创始人的说法,在2026年第二季度增加了4000万美元的年度经常性收入(ARR)。
如果Runway关于视频生成是通往世界模型的道路的赌注成功,其结果将从好莱坞影响到药物发现和机器人技术。如果不成功,Runway就有可能被资金远为雄厚的竞争对手——其中Google首当其冲——超越。
世界模型:科学的数字基础设施
在过去的六个月里,这家创业公司已经将其计划付诸行动,扩展到视频生成之外,在12月推出了它的第一个世界模型(AI系统可以足够好地模拟环境来预测它们将如何行为),并计划在今年推出另一个。
Germanidis将世界模型视为科学基础设施。你在单个模型上训练的感觉数据和观察越多,你就越接近宇宙的工作数字孪生——一个你可以比任何实验室都快地运行实验的模型。
“如果我们能建立一个比人类科学家更好的科学家,我们就能加速我们理解宇宙和解决问题的方式。” —— Anastasis Germanidis
竞争加剧:不缺对手
Runway在追求将物理感知的视频模型转化为世界模型方面并不孤单,近期应用案例包括交互式娱乐、游戏和机器人训练。初创公司Luma和World Labs也处于类似的轨迹上,Google也将其Genie世界模型指向同一方向。
所有人都在追求某种版本的同一件事:解决人类最困难问题的AI。这与Runway的原始产品相去甚远,但这是技术中突现能力和创始人倾向于跟随它引导的结果。
Runway能否将其视频主导地位带入世界模型还远未确定,竞争也不会等待。Runway是首批开发AI视频生成的公司之一,但世界模型是一场不同的竞赛,有资金雄厚且备受尊敬的竞争对手。Google、前Meta首席科学家Yann LeCun、AI的”教母”Fei-Fei Li,以及越来越多的初创公司都在追逐同一个目标。
资源和挑战
AI技能基准公司Workera的CEO兼斯坦福大学讲师Kian Katanforoosh指出,还没有人证明通过世界模型在视频智能和通用推理之间的跳跃,但这并不意味着不可能。他说,如果Runway想将其世界模型赌注变为现实,就需要继续收集资源——其中计算能力首当其冲。
Runway与CoreWeave和Nvidia有协议,但不愿确认是否有专用的集群访问权限——这是训练前沿模型所需的有保障的大规模计算。
“没有集群,你要如何建立基础模型?我不认为任何人能做到。” —— Kian Katanforoosh
Runway迄今为止已筹集了8.6亿美元,包括2月份来自AMD Ventures和Nvidia等战略合作伙伴的3.15亿美元轮融资。根据PitchBook的数据,这与其最直接的竞争对手Luma AI和World Labs大致一致,后两者分别筹集了9亿美元和12.9亿美元。
但Runway也要面对现任者如OpenAI(根据CEO Sam Altman的说法已筹集约1750亿美元)和科技巨头Google的竞争,其母公司的价值为4.86万亿美元。Google是Runway的最大威胁。该公司的Veo模型直接与Runway的视频生成业务竞争,而其Genie世界模型针对的是Runway正在冲刺的同一长期领域。
Runway的优势:不按常理出牌
Katanforoosh并没有把Runway排除在外。他指向AI音频初创公司ElevenLabs,该公司在自己的基准测试上超越了OpenAI和Google,尽管缺乏任一公司的资源和血统。他认为,Runway可以遵循类似的剧本。
这种比较并没有失去Runway创始人的注意。Valenzuela说,创业公司缺乏湾区的”标准化”给了他们优势。他认为,他们不仅有思想的多样性,而且没有硅谷的关系,他们必须更加精明,缺乏许多同行可以获得的战争基金,这些基金本可以使他们不必在早期生成收入。
根据Runway首席运营官Michelle Kwon的说法,尽管计算需求随着规模增加,公司并不急于筹集更多资金。
早期投资者、Compound的管理合伙人Michael Dempsey告诉TechCrunch:”他们的背景让他们能够早早出发,比不更频繁地正确,并建立一种移动得非常快的文化。”
对Valenzuela来说,这种文化始于他首先如何看待世界。他会把任何空闲时间——作为联席CEO和新父亲,时间不多——用来读书,包括智利诗人Nicanor Parra,他描述为Pablo Neruda的对立面:不那么正式,不那么学术,持有一种认为诗歌属于人民而不是规则的观点。
“规则只是他们发明的规则。这是我们在Runway做事的一个驱动力。他们说硅谷在这里,初创公司就在这里。为什么?那些只是编造的规则。把它们都擦掉,重新开始。” —— Cristóbal Valenzuela