LightRAG
轻量级知识图谱RAG框架 – 微软GraphRAG的高效替代方案
📄 EMNLP 2025
⭐ 2.4K+ Stars
📋 项目简介
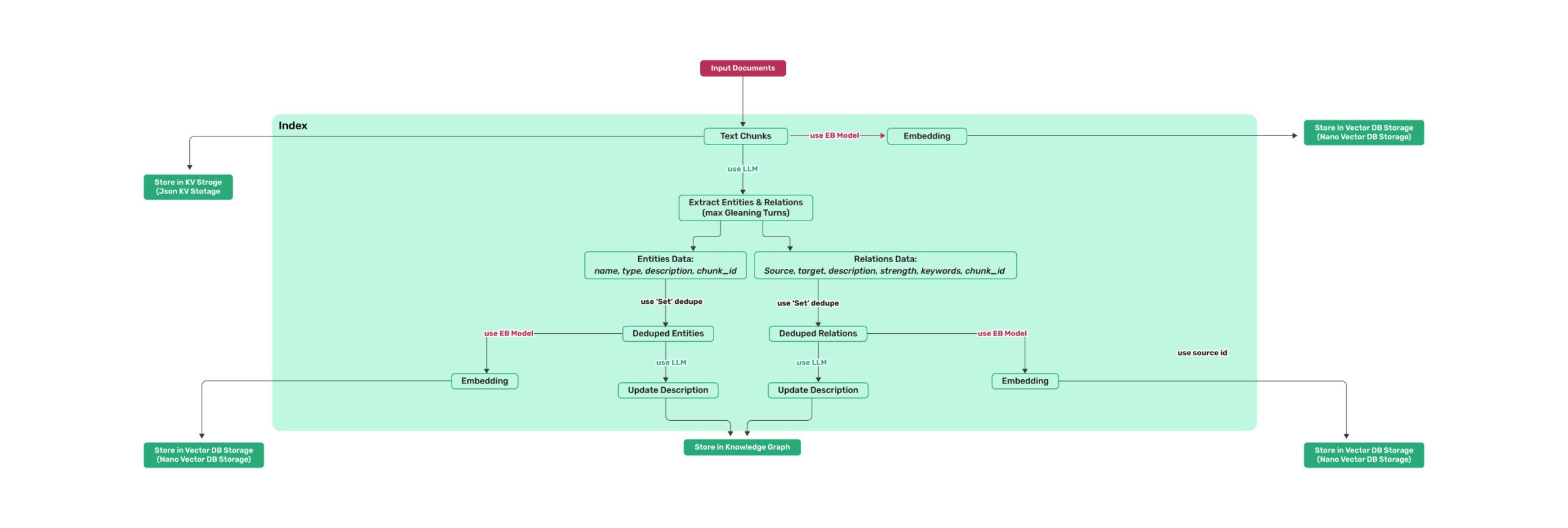
LightRAG 是由香港大学数据科学实验室(HKUDS)开发的轻量级、基于知识图谱的检索增强生成(RAG)框架。作为微软GraphRAG的高效替代方案,LightRAG专为法律、医疗、金融等复杂文档分析场景设计,支持多模态文档处理。其创新的双层级检索架构同时管理知识图谱(KG)和向量嵌入,解决了传统GraphRAG大规模数据处理时的高算力开销、响应慢、增量更新成本高等瓶颈问题。
⚙️ 安装要求
- Python 3.10 及以上
- 推荐使用
uv包管理工具(比 pip 性能更优) - 前端构建依赖:
bun(如需自行构建WebUI)
快速安装(三种方式)
# 安装带API服务的LightRAG
uv tool install "lightrag-hku[api]"
# 构建前端产物
cd lightrag_webui
bun install --frozen-lockfile
bun run build
cd ..
# 配置环境变量后启动服务
cp env.example .env # 修改.env中的LLM和嵌入模型配置
lightrag-servergit clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
# 一键初始化开发环境(自动安装所有依赖+构建前端)
make dev
source .venv/bin/activate # Windows用 .venv\Scripts\activate
# 配置环境变量后启动服务
make env-base # 生成.env配置文件
lightrag-servergit clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
cp env.example .env # 修改LLM和嵌入模型配置
docker compose up
✨ 核心功能
🔍 双层级检索架构
同时管理知识图谱(KG)和向量嵌入,弥合传统向量RAG和图RAG的技术鸿沟。支持5种查询模式:local(局部上下文)、global(宏观主题)、hybrid(融合模式)、naive(传统向量检索)、mix(默认,最全面)
⚡ 增量更新能力
支持知识库无缝增量更新,新数据通过标准图索引pipeline生成局部图后直接合并到现有图谱,无需重构全局索引。删除文档时可基于构建阶段的LLM缓存快速重建受影响的关系,更新效率极高。
🎯 多模态文档处理
v1.5版本起支持多模态文档分析,文档处理管道支持MinerU、Docling、Native等多解析引擎,可高效提取文档中的文本、表格、公式、图像,实现跨模态实体和关系的统一映射与索引。
💰 成本优势
无需生成低效的社区报告或多跳推理来处理复杂查询,大幅减少索引和查询阶段的LLM调用次数,降低响应延迟和算力成本。在农业、计算机科学、法律、混合领域四类测试集上,性能均显著优于NaiveRAG、RQ-RAG、HyDE、GraphRAG等基线方法。
🗄️ 多存储后端支持
支持4类存储(KV存储、向量存储、图存储、文档状态存储)的灵活配置。生产环境可选择PostgreSQL、MongoDB、OpenSearch等统一后端,也可分别搭配Milvus/Qdrant做向量存储、Neo4j/Memgraph做图存储。
🎯 典型使用场景
📄 场景一:垂直领域复杂文档分析
适用场景:法律合同审查、医疗病历分析、金融研报解读等需要深度上下文理解、逻辑推理的场景。
优势:LightRAG的图索引能力可捕捉实体间复杂语义依赖,生成质量优于传统RAG。例如在法律领域,其全面性指标达到83.6%,远超NaiveRAG的16.4%。
🏢 场景二:大规模知识库构建
适用场景:需要处理海量文档、且知识库需要频繁更新迭代的企业知识库、技术文档站等。
优势:LightRAG的增量更新能力可大幅降低更新成本,支持30B参数级开源模型也可达到高精度。无需每次都重构全局索引,显著提升运维效率。
🚀 场景三:生产级RAG系统部署
适用场景:企业级RAG应用,对高可用、低延迟、安全性有严格要求。
优势:可通过配置统一存储后端、本地部署嵌入/重排序模型、调整并发参数,满足企业级部署需求。支持引用溯源、文档删除、RAGAS评估集成、Langfuse链路追踪等生产特性。
💡 推荐理由
作为一名经常与RAG系统打交道的开发者,我必须说 LightRAG 是我近期见过的最务实的RAG框架创新。它并没有试图颠覆什么,而是精准地解决了GraphRAG在实际落地时的三大痛点:算力开销高、更新成本高、响应速度慢。
最让我印象深刻的是它的增量更新能力。在传统GraphRAG中,每次添加新文档都需要重构整个知识图谱,这在动态知识库场景下几乎是不可接受的。而LightRAG通过局部图合并策略,实现了真正的无缝增量更新,这让它在企业级应用场景中具备了极强的竞争力。
另外,它的多模态支持也非常实用。在现代文档中,表格、公式、图片的信息同样重要,但传统RAG往往只能处理纯文本。LightRAG v1.5通过集成MinerU、Docling等解析引擎,真正实现了对复杂文档的全面理解。
当然,它并不是完美的。相比成熟的商业化方案,LightRAG在文档量和用户友好度上还有提升空间。但考虑到它是开源且活跃维护的项目,而且已经有EMNLP 2025论文背书,我相信它会成为RAG领域的一个重要里程碑。
适用人群:如果你正在构建需要处理复杂文档的RAG系统,或者对GraphRAG的性能和成本不满,LightRAG绝对值得一试。特别是对于法律、医疗、金融等垂直领域的应用,它的知识图谱能力会让你事半功倍。
📥 下载地址
LightRAG 为RAG系统提供了一种更高效、更经济的解决方案。无论是构建企业知识库、垂直领域问答系统,还是进行RAG相关研究,它都是一个值得深入探索的优秀工具。
你是否也在使用RAG技术? 欢迎在评论区分享你的经验和想法!







