2026年5月27日,澳大利亚研究机构Lyptus Research发布了一份让网络安全圈相当震惊的报告:GPT-5.5在316道进攻性网络安全任务中解出了292道,正确率高达92.4%,直接把这套评测体系干到了”饱和”状态——剩下的24道题不足以支撑有统计意义的能力曲线拟合,评估方法宣告失效。
换句话说,用来衡量AI黑客有多危险的尺子,先被AI自己弄坏了。
“我们2025年12月搭建这套测试时,选的还是全球最难的题。2026年3月数据就出现饱和苗头。到5月,饱和已经成为事实。”——Lyptus Research 报告
316道题,覆盖了黑客的”全科”
这套评测不是纸上谈兵。316道任务覆盖了7个基准领域,包括漏洞利用、CTF夺旗赛题目、真实CVE漏洞复现三类,每道题都设置了人类安全专家的完成时间作为基线参考。
GPT-5.5的表现相当于什么水平?Lyptus的评估是:顶级黑客团队的水平。不是脚本小子的水平,是那些能在真实环境中找到零日漏洞、写出可靠利用代码的人的水平。
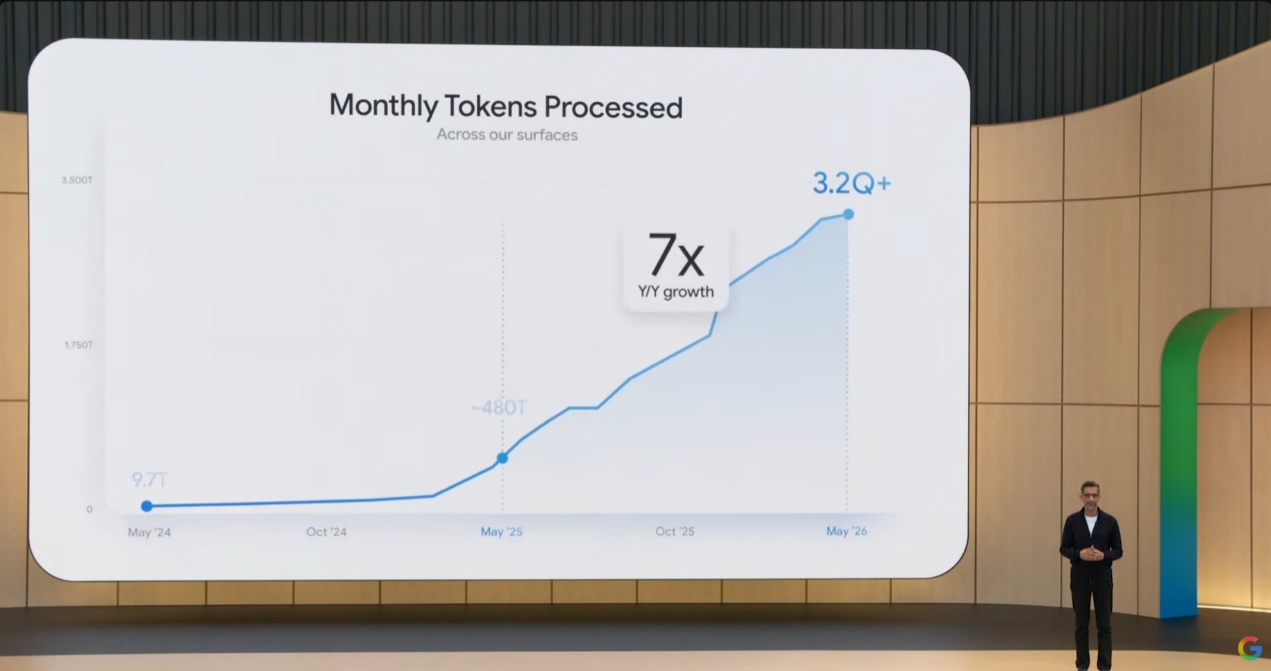
更有意思的是Token预算对能力的影响。在最难的基准CyberGym上,GPT-5.5在200万Token预算下正确率只有54.4%;推到5000万Token时,正确率飙升至86.4%——同一个模型,只因为给的算力更充裕,正确率涨了32个百分点。英国人工智能安全研究所(AISI)的独立研究也证实:给到1亿Token时模型能力仍在上涨,还没看到平台期。
AI黑客能力每5到6个月翻一倍
Lyptus从2024年开始追踪相关数据,拟合出的增长曲线相当吓人:AI进攻性网络安全能力,每5到6个月翻一倍。
这个”时间地平线”指标衡量的是:一个AI系统完成顶级难度任务平均需要多少时间(通过不断增加算力预算来测量)。2026年初,Claude Opus 4.6的时间地平线是3.2小时,GPT-5.3 Codex是3.1小时。两个月后,GPT-5.5的时间地平线直接拉到了5.1小时——如果放开算力上限让它冲过12小时的测量上限,这条曲线根本画不出来。
问题在这里:时间地平线方法论原本的假设是,总会有比当前模型能力更难的题来锚定曲线的拐点。但GPT-5.5把所有题都做完了,拐点消失了,曲线无法拟合。评测体系不是被证伪了,是被模型能力的增长速度远远甩在了后面。
头部厂商已经在”控”了
意识到这个能力水平意味着什么之后,头部厂商的动作相当迅速:
- Anthropic:4月发布Claude Mythos Preview,但因为网络安全能力过强,决定不公开发布。配套推出了Project Glasswing,只把模型部署给关键基础设施的防御方使用。
- OpenAI:给GPT-5.5的网络安全能力评级为”High”(只比最高级”Critical”低一档),所有攻击相关能力均通过”Trusted Access for Cyber”门控,不是谁都能调用。
- METR独立评估:拟合出Claude Mythos的时间地平线至少为16小时,但无法给出精确点估计——这意味着连独立评估机构都跟不上模型的边界了。
最麻烦的问题:闭源能力迟早会开源
Lyptus测量了一个叫”适应缓冲期”的指标:从一个闭源前沿能力首次出现,到同等能力出现在开源模型里,平均时间差是多少。在进攻性网络安全领域,这个数字是5.7到13.1个月。
按当前的速度,Mythos和GPT-5.5级别的攻击能力,2026年年内就可能以开源形式落到任何人手里。到那时候,没有”Trusted Access”门控,没有使用场景限制,只有一块显卡和一点好奇心。
网络安全圈子里的普遍看法是:防御方本来就需要假设”攻击者拥有无限资源”,但当一个高中生也能在本地跑一个GPT-5.5级别的攻击模型时,”无限资源”的假设就不再是理论讨论了。
连”最易量化”的领域都跟不上了
这份报告最让人不安的地方,其实不在92.4%这个数字本身,而在于它暴露了一个结构性困境:网络安全是少数有明确成功判据(漏洞找到了没有?系统打穿了没有?)因而相对容易量化的AI能力领域。连这个领域的评估体系都已经失效了,那些更模糊、更难量化的能力维度——推理、规划、社会工程——的评估困境只会更突出。
如果AI能力真的按照每6个月翻一倍的速度增长,一年后是当前的4倍,两年后是16倍。在通往AGI乃至ASI的路上,失效的评估体系只会越来越多,而不是逐渐被修好。
对于安全研究者来说,这份报告给出的信号很直接:静态防御规则已经不够用了。当攻击方可以用AI实时生成针对特定目标环境的漏洞利用代码,防御方也必须用AI来对抗AI——而且是同样聪明、同样快速的AI。