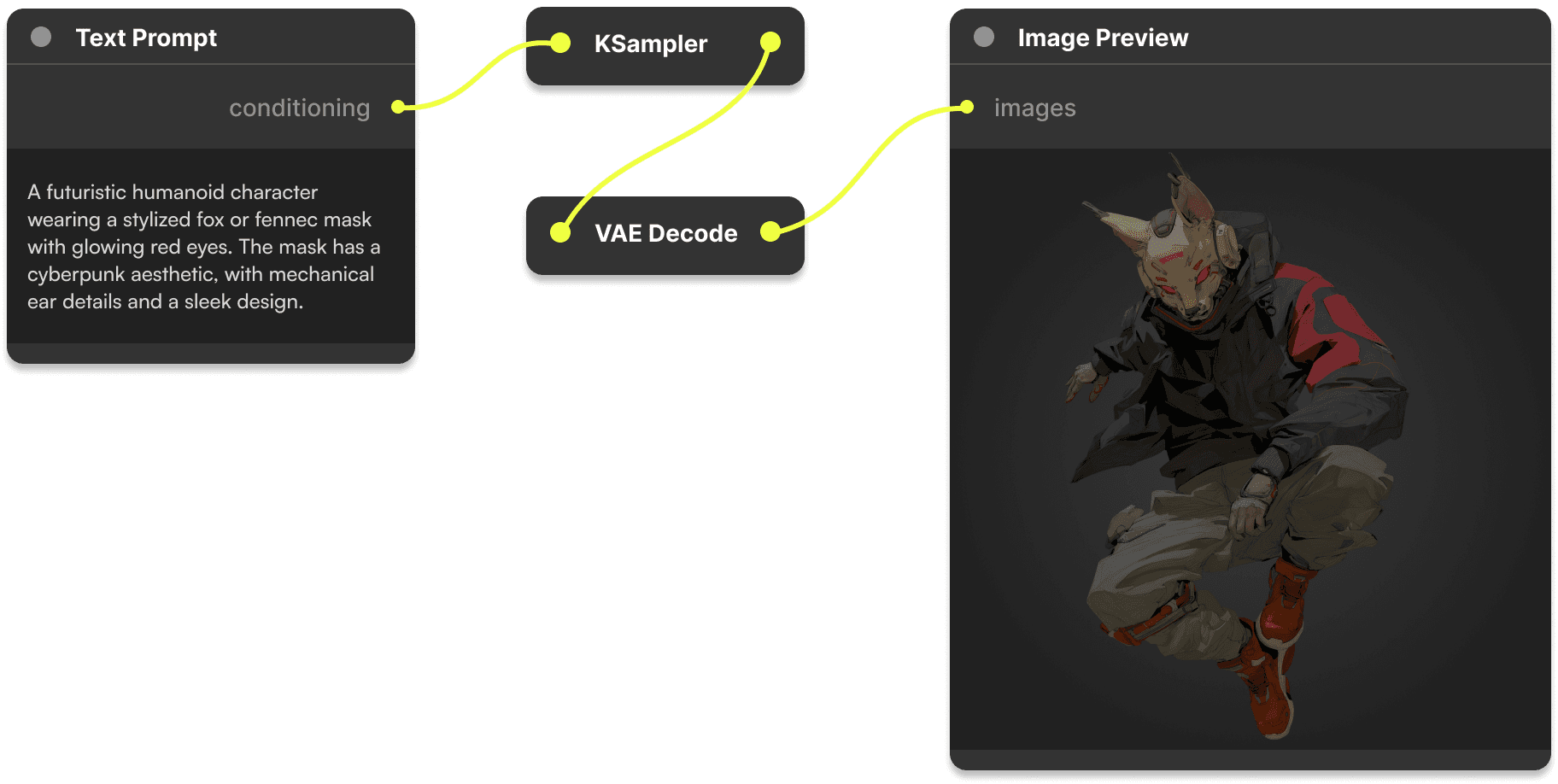
用Stable Diffusion画图的人,大概分两派:一派用WebUI,图个省事;另一派用ComfyUI,追求极致控制力。
我一开始也是WebUI用户,觉得节点式界面太复杂了。直到有一次我想做一个多步重绘+放大+色调调整的流水线,发现WebUI根本搞不定这种复杂工作流,才被硬推到了ComfyUI这边。
结果上手之后回不去了 —— 这种节点式的工作流编排方式,一旦理解了逻辑,创作效率简直是质的飞跃。
🚀 项目简介
ComfyUI 是目前最强大的开源节点式生成式AI引擎,拥有 106k+ GitHub Stars。它通过可视化节点画布,让用户自由组合各类AI模型和操作,实现高度可定制、可控制的内容生成。不仅支持图像生成,还能处理视频、3D、音频等多种模态。
⚙️ 安装要求和过程
📋 环境要求
- 操作系统:Windows / macOS / Linux
- Python 3.13(推荐)或 3.12
- 显卡:NVIDIA(CUDA 13.0)/ AMD / Intel Arc / Apple Silicon(M系列)
- PyTorch 2.4+
- 浏览器:Chrome 143+(推荐)
🚀 快速安装
方式一:便携版(Windows,最简单)
# 下载便携版压缩包,解压即用
# 内置 Python 3.13 + PyTorch CUDA 13.0
# 运行 run_nvidia_gpu.bat 即可启动方式二:手动安装(全平台)
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu130
pip install -r requirements.txt
python main.py方式三:桌面版(Windows/macOS)
# 从 comfy.org 下载桌面安装包
# 支持一键安装,适合新手💡 核心功能
- 🧩 节点式工作流:通过可视化节点画布自由编排AI生成流程,每个节点负责一个独立操作(加载模型、生成图像、调整尺寸等),灵活度和可控性远超传统UI
- 🎨 多模态支持:不仅支持图像生成(文生图、图生图、局部重绘、画面外扩),还能处理视频生成、3D模型创建、音频合成等多种创作场景
- 🔌 丰富的自定义节点生态:Comfy Hub 上有全球创作者分享的数千个工作流和节点插件,一键导入即可使用,持续扩展能力边界
- 🤖 AI Agent集成:支持本地ComfyUI服务器集成、Comfy Cloud API调用和MCP Server对接,可以与Claude、Cursor等AI智能体打通
- ⚡ 高性能推理:原生支持最新开源SOTA模型,API节点可接入闭源模型,推理速度快,内存占用低
📦 典型使用场景
🎨 场景1:AI绘画创作
设计师和插画师用ComfyUI构建个性化图像生成流水线 —— 从线稿上色、风格迁移到批量生成设计稿,一个工作流搞定全流程。相比传统绘图软件,效率提升数倍。
🎬 场景2:AI视频与3D制作
内容创作者利用ComfyUI的视频生成节点和3D模型节点,制作短视频素材、产品展示动画、虚拟场景等。节点式编排让复杂的多步视频处理变得可追溯、可复现。
🏭 场景3:企业级批量生产
电商团队用ComfyUI搭建商品图自动化工作流:批量换背景、批量生成不同风格的Banner、批量处理产品照片。工作流可保存复用,一次搭建持续受益。
⭐ 推荐理由
说真的,ComfyUI的门槛确实比WebUI高一些,但这个”高”是值得的。
我最喜欢的是它的可复现性 —— 每个工作流都是一个完整的生成配方,别人拿到你的工作流文件就能一模一样地复现结果。这在团队协作中太重要了,不用再”调参数调到手抽筋还说不清楚用了什么设置”。
而且ComfyUI的社区生态非常活跃,Comfy Hub上各种神仙工作流应有尽有。不会搭工作流?直接下载别人的改一改就行。这就好比从”自己写代码”进化到了”调用开源库”。
最近ComfyUI还加入了AI Agent集成能力,支持MCP协议,这意味着你可以让Claude、GPT这些AI智能体直接帮你设计和调整工作流。AI时代的生产力工具,ComfyUI算是把”可控性”做到了极致。
📧 下载地址
- 🏠 GitHub:https://github.com/comfyanonymous/ComfyUI
- 🌐 官网:https://comfy.org
- 📖 官方文档:https://docs.comfy.org/zh
- 🧩 Comfy Hub:https://comfy.org/workflows
- 💬 Discord:https://discord.gg/ComfyUI







