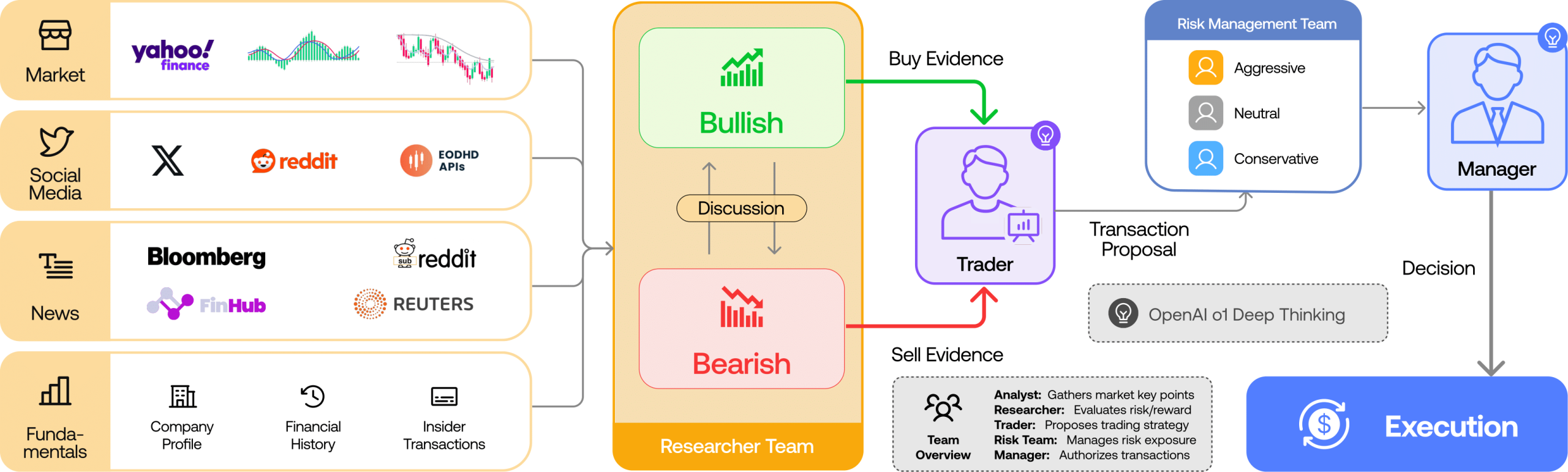
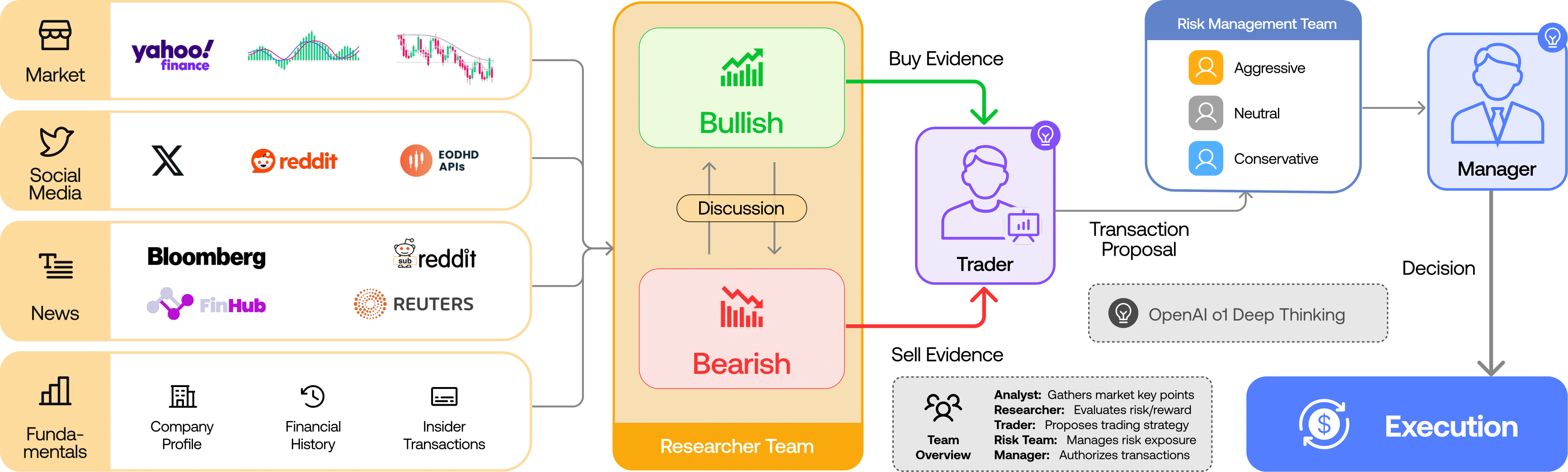
说实话,当我看到2026年4月这波中国AI编码模型的密集发布时,第一反应是:那个”中国AI落后6-9个月”的老框架,真的该扔进历史垃圾桶了。
12天,4家实验室,一场静悄悄的能力赶超
从4月底到5月初,短短12天里,4家中国AI实验室接连发布了各自的最新编码模型,而且全部是开源权重。这可不是小打小闹的demo,而是实打实能打的工程级模型:
- Z.ai的GLM-5.1
- MiniMax的M2.7
- Moonshot的Kimi K2.6
- DeepSeek的V4
最关键的是,它们在SWE-Bench Pro这个权威编码基准上的得分全部落在56-59分区间——什么概念?这个得分已经和西方前沿模型持平了。
价格才是真正的杀手锏
如果能力持平还不够震撼,那成本数据绝对让你倒吸一口凉气:这4款模型的推理成本,最高不超过Claude Opus 4.7的三分之一。
我觉得这里有个被很多人忽略的逻辑:AI能力如果可以低价获取,那么”前沿模型的护城河”到底在哪里?如果Kimi K2.6或者DeepSeek V4能以1/3的价格做到Opus 4.7差不多的事情,那企业采购决策会不会悄然生变?
这不是简单的性价比问题,而是整个AI供应链的话语权在转移。
“落后6-9个月”为什么不成立?
State of AI报告里有一句话我很认同:”中国落后6-9个月”的旧框架在智能体编码领域已不成立。
NIST的CAISI评估显示,DeepSeek V4的跨域基准综合表现落后美国前沿约8个月,但DeepSeek自己的模型卡显示V4-Pro与Opus 4.6、GPT-5.4持平。两个结论都是对的——只不过评估的维度和基准不同而已。
这其实揭示了一个更深的真相:AI能力的比较,已经不再是单一时间轴上的先后问题,而是评估者、支架工程、基准设计的综合博弈。当多个最优模型来自中国且为开源权重时,”追赶者”这个标签就已经失效了。
开源权重:中国AI的”农村包围城市”?
还有一个细节值得琢磨:这4款模型全部开源权重。我觉得这不是巧合,而是一种极其聪明的战略选择。
开源意味着什么?意味着全球开发者可以本地部署、可以微调、可以嵌入自己的产品而不用看任何人的脸色。当西方实验室还在纠结”该不该开源”的时候,中国实验室已经用开源完成了全球开发者生态的布局。
Kimi K2.6发布时展示了一个12小时连续工具使用轨迹,演示了将推理引擎移植到Zig的完整过程——这种”晒能力”的方式本身就很有说服力,比发一篇论文直观多了。
这件事的真正影响可能还没显现
我觉得现在讨论”中国AI是否赶超”还为时尚早,但有一个趋势已经很清晰了:在整个AI领域最具经济影响力的能力(编码和智能体工程)上,多个最优模型来自中国且为开源权重,这件事的长期影响可能被严重低估了。
企业采购、开发者工具链、云服务定价、甚至AI安全的研究议程——所有这些都将因为这个变化而重新调整。我不是在说”中国AI已经全面领先”,而是说”全面落后”这个叙事已经失去了事实基础。
参考资料:State of AI: May 2026, Air Street Press