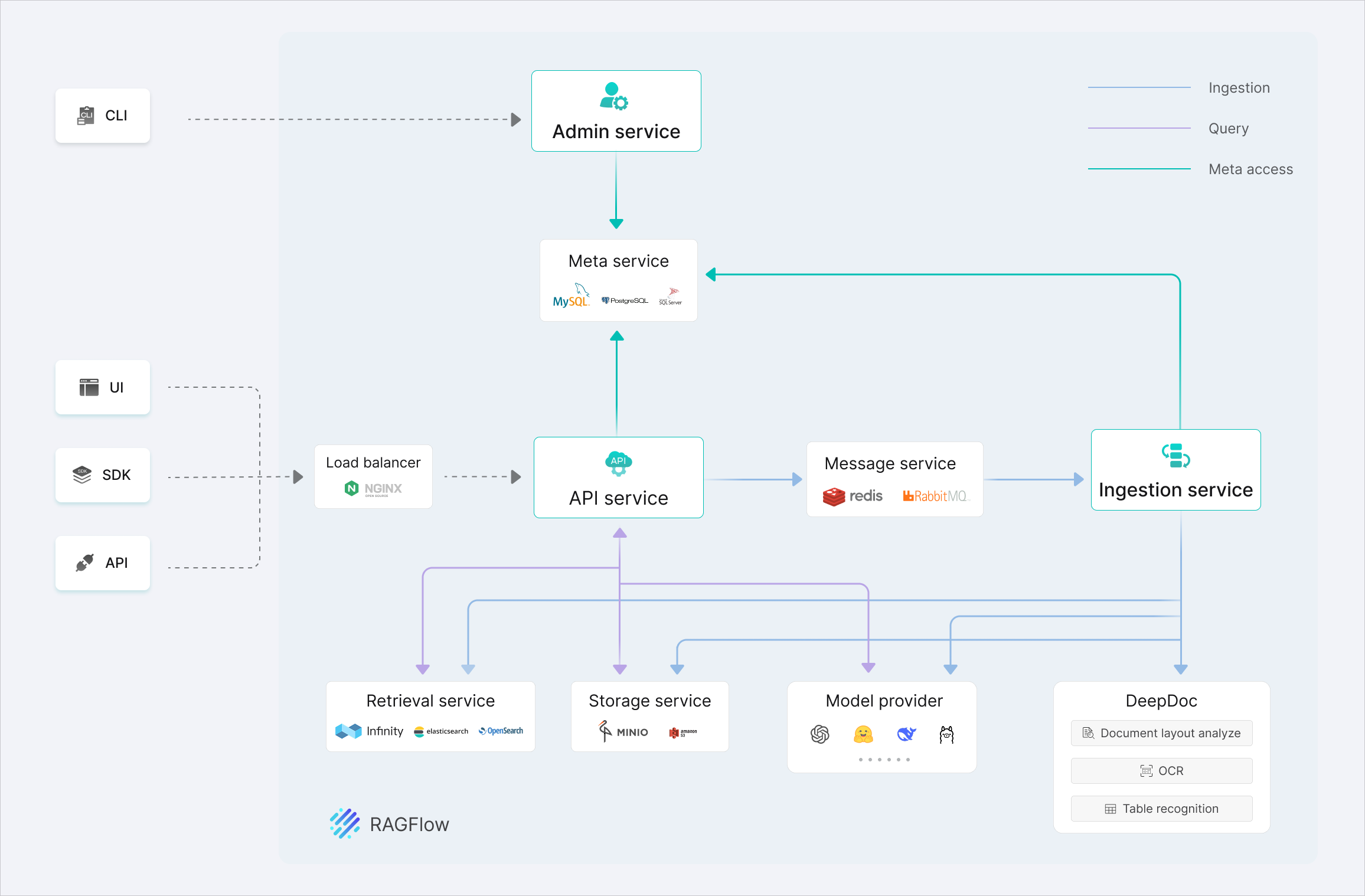
梁文锋掏了200亿,DeepSeek终于开门拿钱了
深度求索(DeepSeek)这轮融资消息出来时,不少人第一反应是:他们不是一直说自己有钱不需要融资吗?事实也是这样——从成立到2026年,DeepSeek所有的研发和计算开支都是创始人梁文锋自己出的。现在突然拿了一轮510亿人民币(约74亿美元)的外部融资,估值站上4000亿人民币(约550亿美元),创始人个人在这轮里仍然出了200亿人民币。
也就是说,这轮融资里近40%的钱仍然是梁文锋自己的。剩下的大头来自腾讯、宁德时代,以及中国国家人工智能产业投资基金。这个投资方组合本身就值得琢磨:腾讯能给它微信生态的入口和流量,宁德时代能给它能源和算力基础设施的支持,国家AI产业基金进来,意味着DeepSeek已经被放到国家级AI战略的底牌里了。

但真正让外界在意的是这轮融资的治理结构。腾讯和宁德时代这些商业投资者,拿到的股份有五年锁定期,而且没有投票权。投票权归国家AI产业基金,而且这个基金的股份没有锁定期。换句话说,DeepSeek的战略方向实际上是由国家基金把控的,商业投资者只能拿分红,不能干预公司的技术路线和商业化决策。
DeepSeek在2025年初发布的R1推理模型和V3语言模型,用远低于美国AI实验室的训练成本,达到了接近GPT-4和Claude的水平。这件事直接导致英伟达等AI基础设施股票出现显著抛售,因为市场开始怀疑:如果DeepSeek的方法是对的,那是不是就不需要买那么多GPU了?
这个疑问现在仍然没有确切答案。但DeepSeek拿到74亿美元之后,毫无疑问可以买更多的算力、训练更大的模型。之前他们是因为没钱才被迫把模型做”高效”,现在钱到位了,接下来会往哪个方向走——是继续做高效小模型,还是也加入千亿参数、万亿参数的军备竞赛?——外界只能等他们下一代模型发布才知道。
五年锁定期,意味着什么
腾讯和宁德时代愿意接受五年锁定、无投票权的条件,说明这笔投资更多是战略卡位,而不是财务投资。腾讯需要AI大模型来补微信生态里的智能助手能力,宁德时代需要AI来优化电池管理系统和生产线自动化,两边都有自己的算盘。
五年锁定期还有一个效果:DeepSeek在接下来五年里不用担心投资人逼着上市、逼着变现。梁文锋之前一直说不想那么快商业化,现在拿了国家的钱和腾讯、宁德时代的钱,反而可以更从容地做研究。当然,反过来说,这也就意味着DeepSeek的技术路线必须符合国家对AI发展的整体布局,不是想做什么就做什么。
对海外客户来说,这个治理结构是一个明确的信号:DeepSeek是一个有国家背景的AI实验室。日本、韩国、印度、东南亚这些市场里,原本因为DeepSeek模型便宜、好用而在考虑接入的企业,现在需要重新评估一遍合规和风险。这也给了那些治理结构更透明、没有国家控股的AI公司一个抢客户的机会。
DeepSeek这轮融资还给亚洲其他国家的AI战略提了一个醒:要做前沿AI,需要多少钱?74亿美元大概是一个基准线。新加坡、日本、韩国、阿联酋的 sovereign fund 如果在2026年开始认真考虑投AI,这个数字是一个绕不开的参考。