北京时间5月20日凌晨,谷歌I/O 2026开发者大会开幕。今年发布会的重点不是某一个单一模型或功能,而是一次系统性转向——谷歌正在把AI智能体全面”塞进”所有核心入口。
从搜索框到Chrome浏览器,从Android手机到智能眼镜,Gemini不再只是一个对话助手,而是一个可以持续运行、跨应用执行任务的AI代理:它能替用户追踪信息、生成内容、调用工具,甚至直接完成下单和操作流程。
谷歌I/O 2026大会现场(图源:新浪科技)
Gemini 3.5 Flash:价格砍半,速度4倍
谷歌CEO桑达尔·皮查伊在主题演讲中发布了新一代大模型系列Gemini 3.5 。首发推出的Gemini 3.5 Flash定位为”迄今最强大的智能体与编程模型”,输出Token速率达到其他前沿模型的4倍 ,而处理智能体任务的费用不到其他前沿模型的一半 。
在GDPval-AA基准(衡量现实世界具有实际经济价值的编程任务)中,Gemini 3.5 Flash取得1656 Elo评分,超过了Gemini 3.1 Pro,也超过了目前公开可查的大部分前沿模型。在Terminal-Bench 2.1(衡量AI在真实终端环境中完成复杂任务的能力)中,得分76.2%——这意味着智能体在执行真实任务时的可靠性,正在从”勉强可用”向”可以依赖”跨越。
皮查伊在演讲中直言:”Flash的惊人之处在于,它以不到同类前沿模型一半的价格,提供了前沿级别的能力。”当一家巨头愿意用”砍半定价”来推广自己的最前沿模型时,它传达的信号不是”我在让利”,而是”我要把竞争对手挤出市场”。
视频模型Omni与智能体编程平台Antigravity 2.0
DeepMind首席执行官德米斯·哈萨比斯登台发布了基于谷歌世界模型技术积累的新型视频生成模型Gemini Omni 。该模型可以基于多种输入生成视频,并支持对话式编辑,用户可以通过自然语言修改角色、背景和场景。首款模型Gemini Omni Flash将于今年夏季推出。
与此同时,谷歌发布了智能体编程平台Antigravity 2.0 ,直接对标Anthropic的Claude Code和OpenAI的Codex。该平台被谷歌定位为面向AI Agent时代的编程工具,官方称其”毫不掩饰地以智能体为先”。使用Antigravity 2.0及其代理系统从零开始构建一个操作系统,整个过程所消耗的Token成本不到1000美元。
个人AI助手Gemini Spark与全线产品整合
谷歌同时发布了全天候运行的个人AI助手Gemini Spark ,基于Gemini 3.5,运行在Google Cloud虚拟机上。用户可以通过Gemini应用访问Spark,即便合上笔记本电脑,Spark也可以继续工作。本周将面向受信任测试人员推出,下周面向美国Google AI Ultra订阅用户开放。
更重要的是,谷歌宣布了全线产品的AI智能体整合计划:
搜索 :将推出搜索信息智能体,后台24/7运行,主动发现信息并代为执行操作;Daily Brief Agent将整合用户的邮件、日历与任务,生成个性化晨间摘要。Android :2026年晚些时候推出Android Halo,为用户提供实时智能体任务追踪界面。硬件 :由Gentle Monster、Warby Parker与三星合作推出的Android XR智能眼镜将于2026年秋季上市,支持语音交互和信息投射。购物 :发布由AI智能体驱动的通用购物车Universal Cart,可在Google服务中使用,追踪优惠、监控价格变动、识别兼容性问题。
规模即壁垒:1800亿美元资本支出背后的逻辑
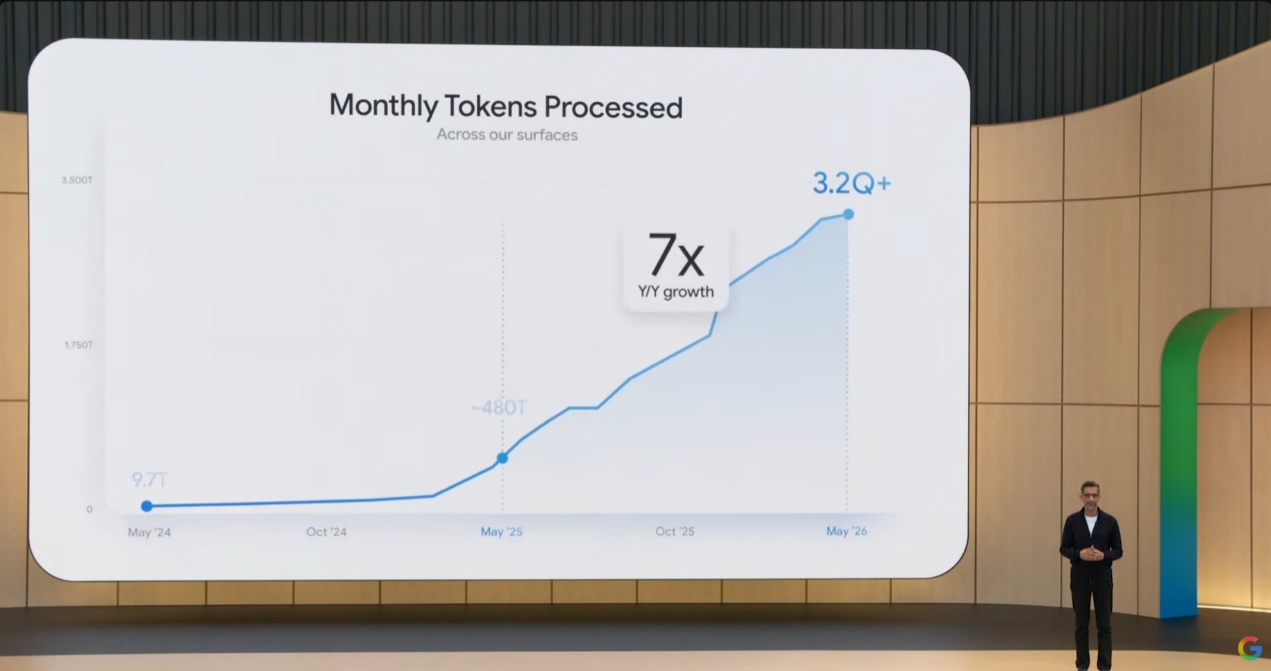
皮查伊在演讲中披露了一组震撼数据:谷歌每月处理的Token数量已达到3.2千万亿 ,同比增长7倍;Gemini App月活跃用户从4亿增长至9亿 ;搜索AI模式月活跃用户突破10亿 。
支撑这一切的,是谷歌2026年预计1800亿至1900亿美元 的资本支出。这1800多亿美元的资本支出,本质上是在做一件事:用基础设施的规模化优势,把竞争对手挤出市场。当你的TPU集群规模、Token处理量和用户基数都达到竞争对手无法匹敌的量级时,”速度4倍、价格砍半”就不再是一个促销手段,而是一个结构性壁垒。
回到根本问题:Gemini 3.5的发布,究竟是一次真正的技术飞跃,还是一次精心包装的战略营销?答案可能是:两者都是。从技术角度看,Gemini 3.5 Flash在基准测试中的表现、推理速度的提升、以及多智能体并行架构的落地,都是真实的进步。但与此同时,这次发布真正值得关注的,不是模型本身,而是谷歌围绕模型构建的全栈壁垒:TPU 8提供算力、Gemini 3.5提供智能、Antigravity 2.0提供平台、Spark和搜索提供触达——这条链条上的每一个环节,谷歌都握有主动权。